i = torch.ones((5, 3), dtype=torch.int16) print(i)
您可以看到,当我们更改默认值时,张量会在打印时有用地报告这一点。
随机初始化学习权重是很常见的,通常使用 PRNG 的特定种子来实现结果的可重复性:
1 2 3 4 5 6 7 8 9 10 11 12 13
torch.manual_seed(1729) r1 = torch.rand(2, 2) print('A random tensor:') print(r1)
r2 = torch.rand(2, 2) print('\nA different random tensor:') print(r2) # new values
torch.manual_seed(1729) r3 = torch.rand(2, 2) print('\nShould match r1:') print(r3) # repeats values of r1 because of re-seed
1 2 3 4 5 6 7 8 9 10 11
A random tensor: tensor([[0.3126, 0.3791], [0.3087, 0.0736]])
A different random tensor: tensor([[0.4216, 0.0691], [0.2332, 0.4047]])
Should match r1: tensor([[0.3126, 0.3791], [0.3087, 0.0736]])
PyTorch 张量直观地执行算术运算。相似形状的张量可以相加、相乘等。标量的运算分布在张量上:
1 2 3 4 5 6 7 8 9 10 11 12 13 14
ones = torch.ones(2, 3) print(ones)
twos = torch.ones(2, 3) * 2# every element is multiplied by 2 print(twos)
threes = ones + twos # addition allowed because shapes are similar print(threes) # tensors are added element-wise print(threes.shape) # this has the same dimensions as input tensors
r1 = torch.rand(2, 3) r2 = torch.rand(3, 2) # uncomment this line to get a runtime error # r3 = r1 + r2
r = (torch.rand(2, 2) - 0.5) * 2# values between -1 and 1 print('A random matrix, r:') print(r)
# Common mathematical operations are supported: print('\nAbsolute value of r:')# 绝对值 print(torch.abs(r))
# ...as are trigonometric functions: print('\nInverse sine of r:')# sin计算 print(torch.asin(r))
# ...and linear algebra operations like determinant and singular value decomposition print('\nDeterminant of r:')# 行列式 print(torch.det(r)) print('\nSingular value decomposition of r:') print(torch.svd(r)) # 矩阵的奇异值分解
# ...and statistical and aggregate operations: print('\nAverage and standard deviation of r:') print(torch.std_mean(r)) # 平均值和标准差 print('\nMaximum value of r:') print(torch.max(r)) # 最大值
A random matrix, r: tensor([[ 0.9956, -0.2232], [ 0.3858, -0.6593]])
Absolute value of r: tensor([[0.9956, 0.2232], [0.3858, 0.6593]])
Inverse sine of r: tensor([[ 1.4775, -0.2251], [ 0.3961, -0.7199]])
Determinant of r: tensor(-0.5703)
Singular value decomposition of r: torch.return_types.svd( U=tensor([[-0.8353, -0.5497], [-0.5497, 0.8353]]), S=tensor([1.1793, 0.4836]), V=tensor([[-0.8851, -0.4654], [ 0.4654, -0.8851]]))
Average and standard deviation of r: (tensor(0.7217), tensor(0.1247))
Maximum value of r: tensor(0.9956)
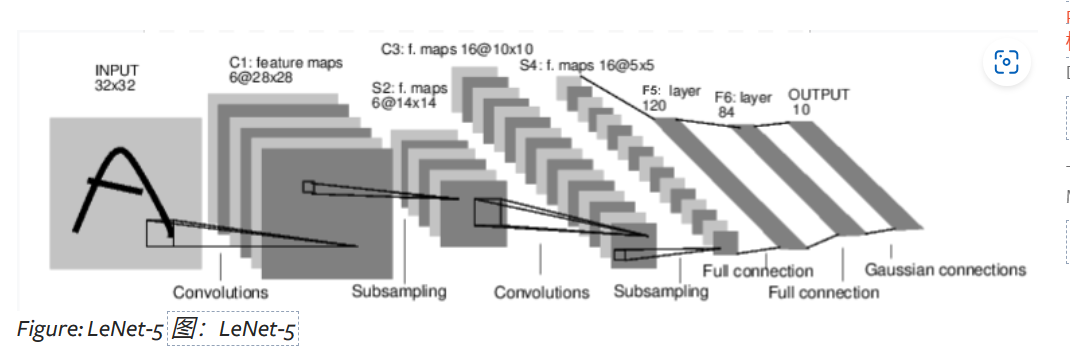
PyTorch Models
我们来谈谈如何在 PyTorch 中表达模型
1 2 3
import torch # for all things PyTorch import torch.nn as nn # for torch.nn.Module, the parent object for PyTorch models import torch.nn.functional as F # for the activation function
defforward(self, x): # Max pooling over a (2, 2) window x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2)) # If the size is a square you can only specify a single number x = F.max_pool2d(F.relu(self.conv2(x)), 2) x = x.view(-1, self.num_flat_features(x)) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x
defnum_flat_features(self, x): size = x.size()[1:] # all dimensions except the batch dimension num_features = 1 for s in size: num_features *= s return num_features
defforward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = x.view(-1, 16 * 5 * 5) x = F.relu(self.fc1(x)) x = F.relu(self.fc2(x)) x = self.fc3(x) return x
correct = 0 total = 0 with torch.no_grad(): for data in testloader: images, labels = data outputs = net(images) _, predicted = torch.max(outputs.data, 1) total += labels.size(0) correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % ( 100 * correct / total))