
论文-02-Super Resolution Based Change Detection Network with Stacked Attention Module for Images With Different Resolutions
Super Resolution Based Change Detection Network with Stacked Attention Module for Images With Different Resolutions(基于叠加注意力模块的超分辨率变化检测网络)
摘要
什么是变化检测:
变化检测(CD)旨在基于双时态图像来区分表面变化。
变化检测通常采用不同分辨率的双时间图像的原因:
由于高分辨率(HR)图像通常不能随时间连续采集,因此在实际应用中,变化检测(CD)通常采用不同分辨率的双时间图像。
传统的基于亚像素的CD方法使用的是什么图像:
不同分辨率的图像。
传统的基于亚像素的CD方法当使用HR图像时会存在什么问题:
亚稳态(sub-stantial error accumulation)误差积累。
为什么传统的基于亚像素的CD方法当使用HR图像时会出现亚稳态误差积累:
这是因为组内异质性(intraclass heterogeneity )和组间相似性( interclass similarity)。
为什么需要提出一种新的CD方法?
有必要开发一种新的CD方法,使用更适合HR图像的不同分辨率的图像。
本论文提出的新的CD方法是什么?
本论文提出了一种具有堆叠注意力模块(stacked attention module SAM)的基于超分辨率的变化检测网络(super-resolution-based SRCDNet)
本论文网络模型的构成包含了:
SRCDNet采用了一个包含生成器和鉴别器的SR模块。
生成器和鉴别器的SR模块的作用是:
生成器和鉴别器的超分辨率(SR)模块,通过对抗性学习直接学习SR图像,并克服双时态图像之间的分辨率差异
特征提取器包含了?
由五个卷积块注意力模块(CBAM)组成的SAM
注意力模块(CBAM)组成的SAM的作用是什么?
为了增强多尺度特征中的有用信息。
变化决策模块是如何学习的?
通过基于度量学习的
变化决策模块的作用是什么?
块获得最终的变化图,其中计算双时态特征之间的距离图
本论文的模型在那些数据集上进行了测试?
建筑变化检测数据集(BCDD)和季节变化检测数据集中(CDD)
在建筑变化检测数据集(BCDD)和季节变化检测数据集中(CDD)上进行了什么研究?
消融研究和对比实验
论文是如何保证泛化性的?
在谷歌数据集上进行的真实图像实验,充分证明了该方法的优越性。
本论文源码地址:
https: //github.com/liumency/SRCDNet
简介
变化检测作用
识别同一区域的双时图像中的地表变化
变化检测的作用
- 土地资源调查
- 生态监测与保护
- 城市规划
- 提供定量数据
变化检测特点是
- 由于其能够以高的时间效率提供大范围地表的丰富信息
多光谱卫星图形在过去几十年的发展应用在了多光谱卫星图像。
传统的对于光谱分析的CD方法是什么
- 化向量分析(CVA)[9]
- 主成分分析(PCA)[10]
传统分析方法是怎么进行工作的
- 主要利用双时态图像中的光谱信息
多光谱图像本身具有什么特点,这样的特点有导致了什么问题?
- 图像的光谱分辨率和空间分辨率相互制约,多光谱卫星图像的空间分辨率通常较低,难以实现精确的CD。
目前的遥感的发展导致在过去的几十年里,多光谱卫星图像高分辨率图像已成为CD的主要数据源,尤其在细粒度场景,如城市更新[11]。
新的方法是什么,他为什么能解决这个问题。有哪些方法?
- 基于深度学习的方法
- 深度学习的方法,包括强大的特征学习结构,即卷积神经网络,从HR图像中分层提取空间和语义特征[12]
- 基于分类的方法[13]-[15]
- 基于度量学习的方法[16]、[17]。
HR图像优点:
改善地球表面现象的特征
HR图像存在问题:
观测范围小、时间分辨率低以及云和雾的影响
造成HR图像存在问题的原因:
气象和技术影响
这些问题对HR图形会有什么影响:
限制HR图像调查的实际能力和影响
传统的变化检测的方法特点:
依赖相同分辨率的双时图像分析。
为什么传统的变化检测的方法不能够解决遥感的变化检测问题?特别是在大规模下。
让我们假设我们在时间T1获得了某个区域的HR图像,但只有与时间T2相对应的低分辨率(LR)图像可用;然后,我们需要使用不同分辨率的双时态图像来检测T1和T2之间发生的变化。因此,为了实现大规模和快速的CD,通常需要在现实应用中使用不同分辨率的双时态图像[18]-[20]。
说明现实中大多数时候的不同时间的遥感的图像的分辨率是不同的。
传统的方法是怎么解决这样的问题的?
最直观的方法是简单地将HR图像下采样到LR图像的分辨率[21],或者将LR图像插值到HR图像的分辨率,以获得具有相同分辨率的双时态图像[22],然后使用常见的CD方法来检测变化。
这两种方法分别由什么问题?
第一种方法核心的下采样步骤导致缺乏结果的详细空间信息,这导致所获得结果的精度严重下降。
第二种方法没有考虑应用于遥感图像的常见插值操作(如线性、双线性和双三次插值)中的语义信息,这导致实现感兴趣区域的详细信息的能力不足。
除了最简单的插值方法外还有什么方法解决不同分辨率下的图像问题?
在这种情况下,基于亚像素的方法是最普遍的。
亚像素映射(SPM)从粗分辨率图像中获得精细分辨率土地覆盖图 具有优异能力[23]-[25]。
Ling等人[26]首先将SPM引入CD,使用不同分辨率的图像(简称“不同分辨率CD”),提出了一种空间模式。
什么空间模式:
亚像素尺度的LCC地图的空间模式
手段是:
空间相关性原理
一种新的土地覆盖变化(LCC)规则
Wang等人[27]提出了一种具有SPM的Hopfield神经网络,以克服陆地卫星和中分辨率成像光谱仪(MODIS)图像在亚像素分辨率LCCs中的分辨率差异。
李等人[28]将迭代超分辨率CD方法应用于陆地卫星MODIS CD,该方法结合了端元估计、光谱分解和SPM。
吴等人[29]提出了一种反向传播神经网络,用于从软分类中获得亚像素LCC图
SPM方法是什么方法,在上面方面是有效的,在HR图形上存在什么问题,为什么要开发新的CD方法。
这些基于SPM的方法通过在以前的精细分辨率土地覆盖图和粗分辨率图像之间建立映射来获得精细分辨率变化图,并且已被证明在处理遥感图像CD的大尺度差异方面是有效的,特别是在陆地卫星和MODIS图像上。然而,在这些情况下,精细分辨率变化图的精度在很大程度上受到前一精细分辨率土地覆盖图精度的限制,导致冗余误差积累。由于HR图像中的组内异质性和组间相似性,这样的问题对于HR图像来说将更加严重。因此,迫切需要为不同空间分辨率的HR图像开发更精确的CD方法。
本论文提出的网络基于什么的?做什么用的?本论文呢是如何解决冗余错误的问题的?对SR图像和HR图像是怎么处理的?以及SAM的组成和作用是什么?对比损失的作用是什么?
在本文中,我们提出了一种端到端的,基于超分辨率的,用于不同分辨率变化检测的,变化检测网络(SRCDNet)。为了解决双时态图像空间分辨率不匹配的问题,SRCDNet采用超分辨率模块(SRM)直接从LR图像中学习超分辨率图像,以恢复更多的语义信息并避免冗余错误。然后将SR图像与对应于其他时间戳的HR图像一起输入到特征提取器中。为了充分提取HR图像中的多级信息,以便于后续预测,还将由五个卷积块注意力模块(CBAM)组成的堆叠注意力模块(SAM)添加到特征提取器中。然后,为了从双时态图像的多尺度特征中学习精确的变化图,计算特征之间的距离图,并将其与基本事实进行比较,其中采用对比损失(度量学习中的常见损失)来帮助增加变化区域的距离,减少不变区域的距离。最后,可以通过简单的阈值处理从距离图中获得变化图。
本论文研究的贡献,如何解决了误差积累的问题,如何有效的提取层次特征,进行了那些研究保证了精度。
1) 我们提供了一个端到端的基于超分辨率的HR图像光盘网络;所提出的方案通过LR图像和初始HR图像之间的映射来学习SR图像,以避免传统的基于亚像素的方法中遇到的误差累积。
2) 我们将由五个CBAM块组成的SAM集成到网络的特征提取器中,以增强层次特征中的有效信息,获得更可区分的特征对,这可以通过度量学习极大地帮助后续的变化决策。
3) 在两个常见的变化检测数据集(CDD)上进行了比较实验,即构建变化检测数据集中(BCDD)[30]和CDD[31],以验证SRCDNet的有效性,并构建了一个基于谷歌数据集[32]的真实图像数据集,以在真实图像上进一步测试SRCDNet。结果表明,该模型不仅在BCDD和CDD中模拟的不同分辨率图像上具有最先进的SOTA性能,而且在真实图像上也获得了最高的精度。
本文的结构
本文的其余部分组织如下:第二节进一步介绍了一些相关工作。第三节介绍了关于拟议网络的详细信息。第四节阐述了本研究中进行的所有实验的设置。在第五节中,我们介绍了我们的结果和详细分析。第六节讨论了不同设置对模型的影响。最后,我们在第七节中总结这篇文章。
相关工作
A. 基于深度学习的CD
在全卷积网络(FCN)[33]提供了一种更直观的密集预测方法之后,许多基于FCN及其变体,
特别是U-Net [34]的方法已被提出用于像素级CD。
Daudt等人[14]基于U-Net探索了三种不同的图像输入方法,包括早期融合、Siamese_difference和Siamese_concatenation,用于双时相CD。
为了充分利用双时相图像中的全局和局部信息,Peng等人[35]提出了U-Net++,采用多尺度特征融合策略生成最终的变化图。
U-Net的编码器-解码器结构通常用于语义分割任务,其中编码器用于提取双时相图像的多级语义特征,解码器用于从分层特征中恢复空间信息,并通过分类生成CD图。
近年来,一些研究将度量学习引入CD中,以替换解码器的上采样过程,通过计算双时相图像的特征之间的距离直接获得变化图。
在训练过程中,“未更改”特征之间的距离被最小化,而“更改”特征之间的距离被最大化;损失函数在此过程中起着重要作用。
例如,Zhang等人[36]使用改进的三元组损失来学习成对特征中多尺度信息之间的语义关系。
Wang等人[37]使用对比损失来检测基于使用Siamese卷积网络提取的特征的变化。为了减轻CD中类别不平衡的影响,Chen和Shi[16]采用批量对比损失来训练所提出的时空注意力网络(STANet)。
B CD策略
虽然高分辨率(HR)图像由于组内异质性和组间相似性的影响而导致误报警或漏报警,但已经尝试了许多方法来生成更具有区分性的特征,包括循环神经网络(RNN)[38]和注意机制。
Papadomanolaki等人[13]将长短期记忆块(LSTMs)[39]集成到FCN中,以检测Sentinel-2图像中的城市变化,并证明了RNN对于捕捉图像之间的光谱或时间关系是有效的。
此外,Song等人[40]将卷积LSTM与3-D FCN相结合,以捕获高光谱图像中的联合光谱-空间-时间特征。尽管RNN可以在多光谱和高光谱输入上很好地工作,但由于HR图像中光谱信息不频繁和双时相图像中时间信息不足,它们仍然受到限制。
由于注意机制能够增强提取特征中的有用信息,因此已经采用注意机制更好地利用HR图像中丰富的空间信息。
Chen和Shi[16]在CD网络的特征提取器中集成了自注意模块,以加强双时相特征之间的时空关系。Chen等人[17]为每个双时相特征使用双CBAM [41]来强调图像中的变化信息,从而促进了基于度量学习的变化决策。然而,由于内存限制,在现有的有效利用空间信息进行CD的方法中,注意机制通常仅应用于高级语义特征,而忽略了浅层特征的增强。
C 超分辨率
由于图像质量在许多视觉应用中起着至关重要的作用,超分辨率旨在从LR图像中获得更高质量的图像。近年来,深度学习的繁荣为图像超分辨率带来了新的解决方案,特别是针对单幅图像超分辨率(SSIR)。为了在从LR图像重建HR图像时更好地恢复图像的详细信息,Dong等人[42]首次将CNN引入SR应用程序作为超分辨率卷积神经网络(SRCNN)。此后,研究人员已经相继提出了一系列有效的SR算法。Kim等人[43]通过将SRCNN和Visual Geometry Group(VGG)骨干结合起来,设计了一个名为very deep super-resolution(VDSR)的具有20层的深度神经网络。Kim等人[44]还为SR提出了一种深度递归卷积网络(DRCN)。鉴于生成对抗网络(GANs)[45]在其他各个领域的出色表现,Ledig等人[46]将GAN应用于SR,并提出了超分辨率生成对抗网络(SRGAN),该网络在当时实现了SOTA性能。结合上述研究,我们提出了一种深度度量学习变化检测网络(CDNet),将超分辨率集成到其中,以学习从LR图像到HR图像的映射,并使用注意机制获取更有效的多尺度特征,用于不同分辨率的CD。
III. 方法论
本节提供了所提出方法的简要概述,随后详细描述了每个部分及模型的优化过程。
A. 概述
SRCDNet如图1所示,由两部分组成:超分辨率(SR)模块和CD模块。基于GAN架构,SR模块由生成器和判别器组成,旨在将双时相图像的LR图像重建为HR图像。CD模块负责特征提取和CD。特征提取器中集成了一个SAM和五个CBAM,这是一种轻量级的注意机制,可以增强特征的通道和空间信息,以提取多尺度特征。之后,采用深度度量学习进行后续变化决策。
假设我们需要检测在T1获得的高分辨率(HR)图像和在T2获得的低分辨率(LR)图像之间的变化,其分辨率差异可以表示为N(N = 4,8)。给定T1和T2的一组HR双时相图像,分别称为$$ I^{HR}{T1}$$和 $$I{T2}^{HR}$$,以及相应的变化注释Y。 $$I_{T2}^{HR}$$将被下采样N次以生成T2的LR图像,可以称为$$I^{LR}{T2}$$。因此,我们可以获得由一组图像$$(I{T1}^{HR},I_{T2}^{HR},I_{T2}^{LR}) = {(i_{T1}^{HR},i_{T2}^{HR},i_{T2}^{LR})^1,…,(i_{T1}^{HR},i_{T2}^{HR},i_{T2}^{LR})}$$^n ,n∈N 组成的训练集,以及地面实况$$ GT = {gt^1,..,gt^n},n∈N$$,然后可以总结SRCDNet的流程如下。
1)将$$I_{T2}^{LR}$$输入SR模块的生成器G,生成器G将生成T2的SR图像,即$$I_{T2}^{SR} = G(I_{T2}^{LR})$$,与$$I_{T2}^{HR}$$相同大小;之后,判别器D负责学习通过损失$${Loss}{d}$$来区分$$I{T2}^{SR}$$和$$I_{T2}^{HR}$$,$${Loss}{d}$$由判别器的输出D($$I{T2}^{SR}$$)和D($$I_{T2}^{HR}$$)构成。
2)然后,$$ I_{T1}^{HR}$$和$$I_{T2}^{SR}$$都被输入到共享权重的特征提取器中,以获得分层特征。在将四个中间特征堆叠成一个之前,应用了前四个CBAM。然后,在堆叠后的特征上应用第五个CBAM块。
3)此后,根据双时相特征$$f_{r1}$$和$$f_{r2}$$计算距离图dt,以测量$$ I_{T1}^{HR}$$和$$I_{T2}^{SR}$$之间的距离,然后与真值gt进行比较,得到对比损失$$Loss_{CD}$$。然后优化度量$$Loss_{CD}$$,以拉开真值上变化区域之间的距离,缩小不变区域之间的距离。
4)最后,根据$$I_{T2}^{SR}$$和$$I_{T2}^{HR}$$之间的差异、判别器的结果和CD性能$$Loss_{CD}$$,优化生成器G,以生成具有丰富语义信息的SR图像。
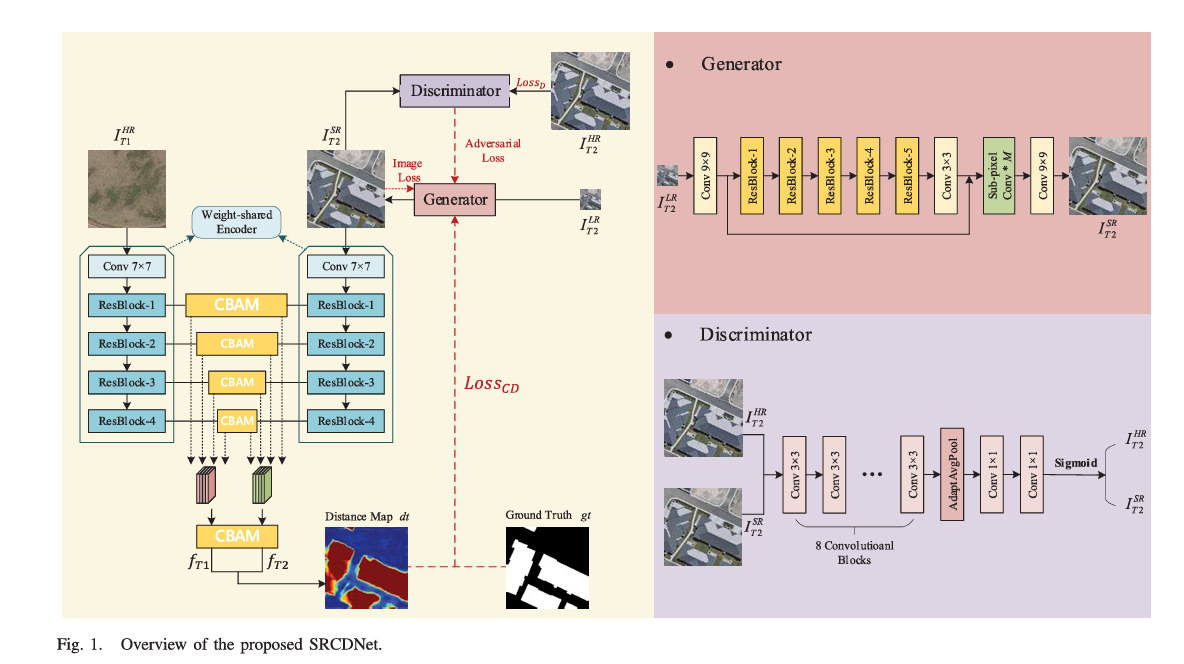
值得注意的是,当双时态图像之间没有空间分辨率差异时,通过去除SR模块,SRCDNet可以很容易地退化为简单的CDNet;这一细节显著提高了模型的通用性。
B 超分辨率模块
SR模块的结构受到了SRGAN方案的启发,其中一个生成器负责从LR图像生成SR图像,而一个判别器负责区分SR图像和初始的HR图像,直到它们彼此无法区分,然后生成器就能够输出足够进行细粒度CD的SR图像。
这段内容是介绍了SR模块的设计原理,它是基于生成对抗网络(GAN)的思想,利用一个生成器和一个判别器来实现超分辨率(SR)的效果。生成器的目标是从低分辨率(LR)图像生成高分辨率(HR)图像,判别器的目标是判断生成的图像是否真实。当判别器无法区分真假时,说明生成器达到了最优,能够输出高质量的SR图像,这对于变化检测(CD)是有利的,因为可以提高检测的精度。
生成器首先使用一个9×9的卷积层来捕获输入LR图像的浅层特征,然后使用五个残差块来提取高层特征。每个残差块由两个3×3的卷积层组成,后面跟着一个批量归一化(BN)层,其中第一个是一个参数化整流线性单元(PReLU)层,作为激活层。残差块进一步提取的深层特征与第一个卷积层得到的浅层特征融合,得到具有丰富空间和语义信息的特征。然后,使用M个子像素卷积层来增加特征的大小,使之与HR图像相同。由于每个子像素卷积层可以通过像素洗牌操作将输入特征的大小放大两倍,所以M的值可以通过M = log2N来计算。最后,生成器通过一个全卷积层产生SR图像。
判别器继承了VGG-19的结构,包含八个卷积层,其中使用了BN层和泄漏ReLU函数。两个全连接层和一个sigmoid函数用于输出输入图像的分布,这是一个二分类任务。由于判别器的目标是区分SR图像和HR图像,所以通过对抗训练可以促使生成器生成更接近原始HR图像的SR样本。
这段内容是介绍了SR模块的生成器和判别器的网络结构,它们分别负责从LR图像生成SR图像和从SR图像和HR图像中进行真假判断。生成器使用了卷积层、残差块和子像素卷积层来提取和放大特征,判别器使用了VGG-19的结构来进行分类。通过对抗训练,生成器和判别器可以相互促进,使得生成的SR图像更加逼真。.
C CD 模块
SR模块的目的是产生与HR图像相似的SR图像,而CD模块的任务是基于SR图像和另一个时刻的HR图像生成精确的变化图。SRCDNet中的CD模块采用度量学习的方法,基于特征提取器的特征来获得变化图。
我们使用一个预训练的ResNet-18作为特征提取器,去掉了最后的全连接层,将其扩展为一个孪生结构,以接收双时相的输入。一个步长为一的7×7卷积层用于提取具有丰富空间信息的浅层特征,后面跟着一个BN层和ReLU函数,然后使用一个步长为二的最大池化层。然后,使用四个残差块来充分利用图像中的信息。每个残差块的输出特征的大小分别是输入图像的1/2、1/4、1/8和1/8,通道数分别是64、128、256和512。
为了充分捕获多尺度特征中的有效信息,我们在特征提取器中集成了一个SAM和五个CBAM。具体来说,四个CBAM块分别应用于每个残差块的输出特征,以强调有用的信息;这些特征然后统一调整为原始图像大小的一半,并融合成具有多尺度信息的特征。然后,第五个CBAM块被应用,以使后续检测的特征对更加可区分。
每个CBAM块包含两部分:一个通道注意力模块,用于捕获通道间的关系,和一个空间注意力模块,用于探索空间间的上下文信息。给定一个大小为C x H x W的特征F,在通道注意力模块中,首先分别对输入特征应用一个平均池化层和一个最大池化层,以得到两个大小为C × 1 x 1的向量,然后使用一个包含两个1 × 1卷积层的共享权重的多层感知器(MLP)模块,来学习并给每个通道赋予权重。最后,将两个因子相加得到一个,然后应用一个sigmoid函数$$\sigma $$,得到通道注意力图因子,可以表示为
$$
M_c(F)=\sigma(MLP(Avg(F))+MLP(Max(F)))
$$
经过通道注意力模块的加权后,得到的通道精化特征F’是$$M_c(F)$$和F的乘积,可以表示为
$$
F’ = M_c(F) \otimes F
$$
然后,空间注意力模块会作用于大小为C x H x W的特征F‘,它与F的大小相同。这里,一个平均池化层和一个最大池化层被用来将F’压缩成两个大小为1 x H x W的矩阵,然后将它们堆叠成一个,并输入到一个3 x 3的卷积层。最后,通过一个sigmoid函数,得到空间精化矩阵,可以表示为
$$
M_s(F’)=\sigma(f^{3*3})(Avg(F’);Max(F’))
$$
因此,CBAM精化特征可以通过以下公式得到:
$$
F’’ = M_s(F’)\otimes F’
$$
由于CBAM不改变输入特征的大小,所以第五个CBAM的输出特征对保持了原始图像一半的大小,之间用欧氏距离来衡量它们的相似度。距离图需要插值到原始图像的相同大小,然后用对比损失作为度量来衡量距离图和真值之间的差异。之后,通过度量的优化,真值上变化区域的距离增加,而不变区域的距离减少。换句话说,我们可以通过度量学习得到距离图,使得变化区域和不变区域之间的值差异尽可能大。因此,我们可以通过阈值分割从距离图中得到更精确的变化图。
D部分损失函数
我们的网络中有三个子模型需要优化:SR模块中的判别器,生成器和CD网络。每个子模型的目标如下所述。
1)判别器:在接收到$$I_{T2}^{HR}$$和$$I_{T1}^{SR}$$作为输入后,判别器输出输入图像为$$I_{T2}^{HR}$$的概率。为了提高判别器准确区分$$I_{T2}^{HR}$$和$$I_{T1}^{SR}$$的能力,判别器的损失函数设计如下:
$$
Loss_D = 1 - D(I_{T2}^{SR}) + D(G(I_{T2}^{LR}))
$$
根据公式,判别器在对抗训练后对高分辨率图像输出接近1的概率,对超分辨率图像输出接近0的概率
2)变化网络:然后,$$I_{T2}^{SR}$$和$$I_{T1}^{HR}$$一起输入到CDNet中,其中用连体特征提取器提取双时相输入的多尺度特征。基于经过CBAM块增强的特征对,计算特征对之间的欧氏距离图,然后根据这个距离图,用阈值分割生成最终的变化图。因此,CDNet的目标是根据真值图,尽可能地拉开距离图上“变化”区域和“不变”区域的对应值。因此,用一个批量对比损失来帮助最小化距离图上“不变”区域之间的距离,最大化“变化”区域之间的距离,可以表示为:
$$
Loss_{CD} = \sum_{i,j=0}^{M}\frac{1}{2}[(1-gt_{i,j})dt_{i,j}^2+gt_{i,j}max(dt_{i,j}-m^2)]
$$
其中M表示dt的大小;dt(i,j)和gt(i,j)分别表示距离图和真值图在点(i,j)处的值,其中i,j∈[0,M);m是用来过滤掉超过阈值的像素的边界,实验中设为2。
3)生成器:生成器的损失由以下几部分组成:图像损失、内容损失、对抗损失和变化损失。图像损失通过计算$$I_{T2}^{SR}$$和$$I_{T2}^{HR}$$之间的均方误差(MSE)来衡量它们在像素空间上的对齐程度。图像损失可以表示为
$$
l_{MSE} = \sum_{i,j=0}^{M}({I_{T2}^{HR}}{i,j}-G(I{T2}^{LR}){i,j})
$$
由于像素对齐很难在图像中保留详细信息,因此内容丢失更多地关注感知相似性。具体地说,内容损失计算通过预训练的VGG-19网络获得的$$I{T2}^{SR}$$和$$I_{T2}^{HR}$$的某些特征图之间的MSE,以产生视觉上更逼真的SR图像。内容损失的公式为
$$
l_{MSE}^{VGG} = \sum_{i,j=0}^{M}(\phi {VGG}(I{T2}^{HR}){i,j}-\phi {VGG}(G(I{T2}^{LR}){i,j}))
$$
虽然鉴别器设计用于区分$$I_{T2}^{SR}$$和$$I_{T2}^{HR}$$,但生成器旨在通过对抗性损失增加鉴别器误判的概率,其定义如下:
$$
l_D = 1 - D(G(I_{T2}^{LR}))
$$
为了使SR图像在像素和感知上与原始HR图像相似,并同时改进CD结果,CDNet中使用的批量对比损失也被添加到生成器的损失中。总之,优化器的优化目标是:
$$
Loss_G = l_{MSE}+al^{VGG}{MSE}+bl_D+rLoss{CD}
$$
其中a,b,r不同损失的平衡因子

这段内容是介绍了CD模块的网络结构,它是基于特征提取器和度量学习的方法来实现变化检测的。特征提取器使用了一个预训练的ResNet-18,通过一个孪生结构来处理双时相的输入,提取出深层的特征。度量学习的方法是根据特征之间的距离来判断是否发生了变化,从而生成变化图。
这段内容是介绍了CD模块中特征提取器的结构,它使用了一个SAM和五个CBAM来增强多尺度特征的信息。SAM是一个空间注意力模块,用于提取空间上的变化信息。CBAM是一个通道和空间注意力模块,用于分别提取通道和空间上的有用信息。特征提取器使用了一个预训练的ResNet-18,通过一个孪生结构来处理双时相的输入,提取出深层的特征。然后,通过CBAM和SAM来对特征进行融合和加权,使得特征更加适合后续
这段内容是介绍了CBAM块的具体计算过程,它包括通道注意力模块和空间注意力模块两个部分。通道注意力模块通过平均池化和最大池化来提取通道间的关系,然后通过一个共享权重的MLP模块来给每个通道赋予权重,最后通过一个sigmoid函数来得到通道注意力图因子。空间注意力模块通过平均池化和最大池化来提取空间间的信息,然后通过一个3 x 3的卷积层来得到空间注意力图因子。最后,通过两个注意力图因子的乘积,得到CBAM精化特征,用于后续的变化检测。
这段内容是关于一种基于CBAM的变化检测方法,它利用欧氏距离和对比损失来度量特征对的相似度,并通过度量学习和阈值分割来生成变化图。
IV实验的设置
A. 数据集
我们的实验使用了三个变化检测数据集(CDDs),它们的概况如下。
建筑变化检测数据集(BCDD):BCDD [29] 提供了 0.2m对 的图像,大小为 32507 x 15354,以及它们之间的建筑变化的真值。由于双时相图像是在地震发生前后选取的,所以这些区域包含了各种建筑变化,包括建筑重建和更新。为了方便模型的训练和测试,我们将图像裁剪成 7434 个大小为 256 x 256 的无重叠的块,然后按照 8:1:1 的比例随机划分为训练集、验证集和测试集。为了避免过拟合,我们对训练集中的图像进行了旋转,以增加数据的多样性。
变化检测数据集(CDD):CDD [30] 包含了 16000 对真实的季节变化的 Google Earth 图像对,大小为 256 x 256,其中包括 10000 个训练样本、3000 个验证样本和 3000 个测试样本。CDD 的空间分辨率非常高,为 3-100 cm,它不仅提供了常见物体(如建筑、道路和森林)的变化信息,还提供了许多细节物体(如汽车和坦克)的变化信息。虽然 BCDD 和 CDD 都是具有相同分辨率的双时相图像的变化检测数据集,但是对于不同分辨率的变化检测实验,还需要进一步的处理。因此,我们对 BCDD 和 CDD 中的 T2 图像进行了 N(N = 4, 8) 倍的双三次下采样,以获得相应的低分辨率图像,用于后续的实验。BCDD 和 CDD 中不同分辨率的样本示例如图 2 所示。
Google DataSet:,它是由中国广州的 Google Earth 图像构建的,19对图像,大小为 0.55m,大小从 1006 x 1168 像素到 4936 x 5224 像素不等。所有的图像都是在 2006 年到 2019 年之间收集的,当时广州正处于快速发展的时期。因此,这个数据集提供了各种形状和大小的建筑变化。在我们的实验中,对于数据集中 T2 时刻的 19 张图像,我们从 Google Earth 上获取了相同日期的分辨率为 2.2-m 的对应图像,从而构建了一个具有 4 倍分辨率差异的真实图像数据集。然后,这个真实图像数据集被切分成 1118 对无重叠的样本对,并按照 6:2:2 的比例划分为训练集、验证集和测试集。训练集通过随机旋转和翻转进行了进一步的增强。重构的真实图像数据集中不同分辨率的样本示例如图 2 所示。


B 实验设计
为了充分验证所提出的 SRCDNet 的有效性,我们设计了三组实验。
I) 消融实验:首先在 BCDD 和 CDD 上进行了消融实验,以测试 SRCDNet 中不同模块的有效性。由于所提出的 SRCDNet 旨在解决双时相图像在变化检测中的分辨率差异问题,因此这部分的实验涉及到四倍分辨率差异(X4)和八倍分辨率差异(X8)的情况。
\2) 对比实验:然后与其他变化检测方法进行了对比实验,以检验 SRCDNet 的优越性。由于 SRCDNet 也可以转化为一个普通的变化检测模型,除了 X4 和 X8 的实验外,还涉及到了没有分辨率差异(X1)的初始图像的实验,以检查模型的灵活性。
\3) 真实图像实验:为了进一步探究 SRCDNet 在真实图像上的效用,我们在具有四倍分辨率差异的 Google 数据集上进行了真实图像实验。此外,我们还将在 BCDD 和 CDD 上训练的模型迁移到 Google 数据集上,以探索现有的大规模变化检测数据集在真实图像上的应用潜力。
C Baselines
为了验证所提出的 SRCDNet,我们引入了五种最先进的变化检测方法作为对比。每种方法的简要描述如下。
- 全卷积-早期融合(FC-EF)[30]:基于 U-Net 结构,FC-EF 网络通过将双时相图像作为多光谱输入进行融合来检测变化。跳跃连接用于将编码器的特征传递到解码器,以恢复每一层的空间信息。
- 全卷积-孪生差异(FC-Siam-Diff)[30]:FC-EF 的一个变体,FC-Siam-Diff 网络将编码器扩展为一个孪生结构,以接收双时相输入并分别提取它们的特征。在差分操作之后,孪生编码器中同一层的特征通过跳跃连接传递到解码器。
- 全卷积-孪生连接(FC-Siam-Conc)[14]:FC-Siam-Conc 也采用了与 FC-Siam-Diff 相同的孪生编码器,但是在将孪生编码器中同一层的特征传递到解码器之前,先进行连接,而不是使用差分操作。
- BiDateNet [14]:BiDateNet 将 LSTM 块集成到具有 U-Net 结构的全卷积网络的跳跃连接中,以学习双时相图像之间的时间依赖性,从而帮助检测变化。
- 空间-时间注意力网络(STANet)[16]:STANet 是一种基于度量学习的变化检测网络,它提供了一个空间-时间注意力模块,以进一步利用特征中的空间信息和时间关系。
需要注意的是,上述所有的基准方法都要求双时相输入具有相同的分辨率,因此在 X4 和 X8 的实验中,低分辨率图像会被双三次插值到原始图像的大小,以便作为对比方法的输入。
D implementations
我们使用 PyTorch 库实现了 SRCDNet。对于总共 100 个训练周期,我们使用了一个初始率为 0.0001 的 Adam 优化器来促进模型的收敛。训练过程中采用了八个批次的大小。BN 和 Dropout 层都被采用来避免过拟合。生成器的损失函数中的 a, b和 r 分别被设置为 0.006、0.001 和 0.001。在训练过程中,每个周期都会计算最新模型在验证集上的准确率,以便及时保存最佳模型。此外,当验证集上的准确率在 50 个周期内不增加时,采用提前停止的策略。所有的基准方法都在 GeForce RTX 2080ti 显卡上运行,以提高训练效率。
我们采用了四个常用的指标来衡量不同方法的变化检测性能:精确度、召回率、F1-分数和 IoU。假设 TP、FP、TN 和 FN 分别表示真正例、假正例、真负例和假负例,那么精确度和召回率可以定义如下
$$
precision = \frac{TP}{TP+FP}
$$
$$
recall = \frac{TP}{TP+FN}
$$
根据公式,精确度表示假警率,而召回率表示漏警率,两者之间存在着权衡。因此,为了获得更全面的评估,F1 分数将精确度和召回率结合起来,可以表示为如下公式:
$$
F1 = \frac{2precision * recall}{precision + recall}
$$
IoU 表示检测结果和真值之间的交集和并集比率,可以直观地表示为
$$
IoU = \frac{TP}{FP+TP+FN}
$$
此外,峰值信噪比(PSNR)和结构相似性(SSIM)被用作衡量通过双三次插值和超分辨率恢复的图像质量的指标。PSNR 是最广泛使用的衡量图像质量的指标,它是基于均方误差(MSE)来计算的。给定一个灰度图像 X 和参考图像 Y,X 和 Y 之间的 MSE 可以表示为
$$
MSE = \frac{1}{hw}\sum_{i=0}^{h-1}\sum_{j=0}^{w-1}[X(i,j)-Y(i,j)]^2
$$
其中 h 和 w 分别是 X 和 Y 的高度和宽度。
然后,图像 X 的 PSNR 可以通过以下公式计算:
$$
PSNR = 10 * log10(\frac{MAX(X)^2}{MSE})
$$
其中 MAX(X) 表示 X 中的最大值。PSNR 的值越大,X 越接近 Y。在我们的实验中,RGB 图像需要转换为灰度图像,以便计算 PSNR。
从上述公式可以看出,PSNR 只关注 X 和 Y 在像素值上的接近程度,忽略了图像的视觉效果。为了弥补这个缺陷,SSIM 通常被用作辅助,它考虑了亮度(/)、对比度(c)和结构(s)三个组成部分。这三个组成部分可以计算为
$$
l(X,Y) = \frac{2\mu x\mu y + c_1}{\mu x^2 + \mu y ^2 +c_1}
$$
$$
c(X,Y) = \frac{2\sigma x\sigma y + c_2}{\sigma x^2+\sigma y^2+c_2}
$$
$$
s(X,Y) = \frac{2 \sigma xy + c_2}{2\sigma x \sigma y + c_2}
$$
其中 $$\mu$$ 和 $$\sigma$$ 分别是均值和方差的操作,c 和 c2 是为了避免除以零而设置的常数。
然后,X 和 Y 之间的 SSIM 可以表示为
$$
SSIM(X,Y)=l(X,Y)*c(X,Y)*s(X,Y)
= \frac{(2\mu x \mu y + C_1)(2\sigma _{XY} + C_2)}{(\mu ^ 2x + \mu ^ 2y + c_1)(\sigma ^ 2 + \sigma^2+c_2)}
$$
SSIM 的范围是 [0, 1],SSIM 的值越大,X 越接近 Y。
V 结果和分析
A. 消融实验
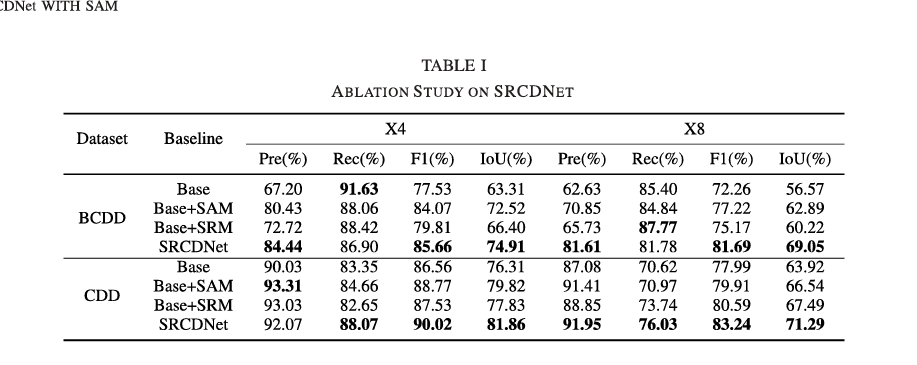
为了验证SAM和SRM的有效性,我们首先在BCDD和CDD上对两种分辨率差异(X4和X8)进行了SRCDNet的消融实验。没有SAM和SRM的SRCDNet被设为基础模型。然后,将SAM添加到基础模型作为第二个基线,将SRM添加到基础模型作为第三个基线。使用LR图像的双三次插值图像作为输入,因为前两个基线不包含SRM。
X4图像的消融实验:如表I所示,基础模型在两个数据集上都表现最差,BCDD上的F1值最低为77.53%,CDD上的F1值最低为86.56%。通过集成SAM,BCDD上的F1值显著提高到84.07%,CDD上的F1值也提高到88.77%。值得注意的是,与基础模型相比,第二个基线的精确率大大提高,这表明SAM可以帮助更准确地提取变化。与基础模型相比,包含SRM的第三个基线也获得了更好的检测结果,BCDD上的F1值为79.81%,CDD上的F1值为87.53%。因此,将SAM和SRM都集成到基础模型中的SRCDNet,在两个数据集上都优于所有基线,BCDD上的F1值最高为85.66%,CDD上的F1值最高为90.02%。
如图4所示,基础模型在两个数据集上的表现都很差。更具体地说,BCDD中的建筑变化有明显的溢出效应,而CDD中对应的变化则大量缺失。第二个基线可以解决上述问题,并且由于SAM的存在,大大提高了检测的准确性。通过集成SRM来生成细粒度的SR图像进行CD,第三个基线的结果具有更精确的变化边界。然而,这还不够准确,因为基础模型的检测性能较差。因此,通过结合SAM和SRM的优势,SRCDNet可以在两个数据集上获得最精确的变化图,基于输出的SR图像。
\2) X8图像的消融实验:在BCDD上对8x LR图像进行的消融实验与对4x LR图像进行的消融实验具有相同的趋势。基础模型只能获得72.26%的F1值,而集成SAM的模型能够将F1值提高到77.22%,集成SRM的模型能够将F1值提高到75.17%。SRCDNet远远超过了上述基线,F1值为81.69%,IoU为69.05%,这充分证明了结合SAM和SRM的可行性。
基础模型在CDD上的表现是所有基线中最差的,F1值为77.99%。虽然在之前的实验中,集成SAM比集成SRM更有效,但在CDD上对8x LR图像进行的实验中,却出现了相反的效果。具体来说,集成SAM的第二个基线的F1值提高到79.91%,而由于添加了SRM,集成SRM的第三个基线的F1值提高到80.59%。这可能是因为SRM可以通过有效地恢复图像信息,增强对CDD中图像中小变化的提取。尽管如此,SRCDNet仍然具有最高的F1值,为83.24%,比其他基线都要高得多。
根据图5,与基于双三次图像的基础模型和基础+SAM模型相比,基础+SRM模型和SRCDNet由于集成了SRM,可以更好地捕捉BCDD上的建筑边界。此外,它们还可以由于SR图像具有更多的细节信息,显著减轻漏报的情况。由于CDD中小物体的信息很难从双三次图像中恢复,基础模型和基础+SAM模型在CDD上得到的变化结果也存在许多漏报。虽然恢复8x LR图像是困难的,但在SRM的帮助下,基础+SRM模型和SRCDNet可以得到更全面的变化结果。
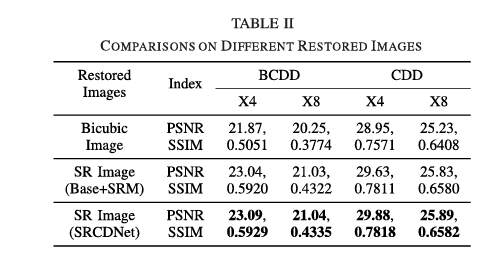
3)不同恢复图像的比较:根据上述的消融实验,有两种不同的方法,双三次插值和SR,可以用来从LR图像中恢复细节信息。虽然Base+SRM模型和SRCDNet都采用了SRM来从LR图像生成SR图像,但对于每组实验,都有三组恢复图像用于CD。因此,我们使用两个常用的指标,即PSNR和SSIM,来定量地比较不同恢复图像的效果,并进一步了解SRCDNet中不同模块的作用。
从表II可以看出,双三次图像在每个比较实验中都获得了最低的PSNR和SSIM。此外,使用Base+SRM模型得到的SR图像的指标有一定程度的提高,这说明SRM可以产生比双三次插值更高质量的恢复图像。使用SRCDNet得到的SR图像在所有实验中都达到了最高的PSNR和SSIM,比使用Base+SRM模型得到的SR图像的指标略高。这进一步证明了前面提到的,SAM和SRM的结合对CD有积极的影响。
另一个值得注意的现象是,在X4图像的实验中,集成SRM导致了PSNR和SSIM的更大提高。因此,与X8实验相比,通过SRM可以恢复更多的图像信息。这表明,分辨率差异越大,图像信息的损失越大,这给图像恢复带来了很大的困难。


B. 比较实验
在X1图像上的性能:如表III所示,我们提出的方法在BCDD数据集上优于所有的基准方法,具有最高的召回率、F1和IoU,分别为90.13%、87.40%和77.63%,以及非常高的精确度84.84%。STANet排名第二,其F1和IoU分别为84.96%和73.86%,分别比我们的方法低2.44%和3.77%。BiDateNet在基于U-Net的方法中取得了最好的结果,其F1和IoU分别为83.55%和71.75%,从而证明了RNNs增强双时相图像中时间关系的可行性。FC-Siam-diff在三种FCN变体中表现最好,其次是FC-Siam-conc和FC-EF。
在CDD数据集上,我们提出的方法和STANet再次取得了最好的性能,这进一步证明了基于度量学习的方法相比传统的基于分类的方法的优越性。虽然我们提出的方法达到了最高的F1和IoU,分别为92.94%和86.81%,STANet则获得了相对较低的F1和IoU,分别为91.44%和84.23%,这表明了SAM的有效性。排名第三的BiDataNet具有最高的精确度95.98%。与BCDD数据集上的结果相反,FC-Siam-conc比FC-Siam-diff表现更好,其F1和IoU分别提高了2.97%和4.44%。这可能归因于CDD数据集包含了各种细粒度的对象,通过跳跃连接中双时相特征的差分操作过滤掉了许多有用的信息,而连接则可以更好地保存特征中的这些信息。上述结果通过可视化比较进一步验证,如图6所示,我们提出的方法获得了最佳的可视化性能。所有的方法都可以准确地提取BCDD数据集中新建的建筑物。此外,FC-EF和FC-Siam-diff存在许多漏报,这与两种方法的低召回率相对应,如表I所示。与其他方法相比,我们提出的方法能够捕捉更精确的建筑物轮廓,这对于实际应用具有重要意义。值得注意的是,我们的方法是唯一一个能够检测到建筑物减少的方法,如图6的第二行所示。
至于CDD数据集,只有对应于大面积的变化才能被三种FCN变体提取出来,这解释了它们的高精度和低召回率,如表I所示。受益于LSTM块的集成,BiDateNet比其他基于U-Net的方法更擅长提取小的变化。两种基于度量学习的方法都擅长捕捉小的变化,包括汽车和道路。STANet可以提取最多的小变化,但结果显示出溢出效应,导致其高召回率但低精度,如表I所示。从可视化结果来看,我们提出的方法不仅可以精确地提取小的变化,而且还可以更好地保持它们的边界和形状。
在X4图像上的性能:如表III所示,当双时相图像之间存在4x的分辨率差异时,与X1图像的实验相比,所有方法在BCDD数据集上的F1和IoU都略有下降。更具体地说,SRCDNet在BCDD数据集上获得了最高的F1和IoU,分别为85.66%和74.91%,分别比X1实验中获得的结果低1.74%和2.72%。虽然STANet在X1实验中优于BiDateNet,但它们在X4实验中获得了相似的结果,其F1分数分别为81.96%和81.97%,这表明STANet更受分辨率差异的影响。在三种FCN变体中,FC-Siam-diff表现最好,其次是FC-Siam-conc,最后是FC-EF,这与X1实验的结果一致。
所有基线方法在CDD数据集上的准确度都下降得更明显。FC-Siam-conc具有最差的检测结果,其F1为73.67%,比X1实验低12.23%。FC-Siam-diff的F1略高,为76.15%。值得注意的是,FC-EF在三种FCN变体中获得了最高的F1,为76.58%,仅比X1实验低2.07%。BiDateNet和STANet的F1值非常接近,分别为86.28%和86.49%,分别比X1实验低3.73%和4.95%。在这种情况下,SRCDNET仍然获得了非常高的F1和IoU,分别为90.02%和81.86%,其F1只降低了2.92%。
这些方法的可视化比较如图7所示。从4x双三次插值图像中,BCDD数据集中的大多数建筑物变化都可以相对完整地检测出来,这表明由于建筑物的尺寸较大,4x的分辨率差异可以在一定程度上通过双三次插值来缓解。这也解释了为什么在X4图像的实验中的准确度只比X1图像的实验略有下降。然而,与SRCDNet得到的结果相比,基于比较方法得到的建筑物变化的边界不够规则和平滑。这可以归因于SRCDNet生成的SR图像可以比双三次插值图像更好地恢复建筑物的边界信息。此外,虽然一些与建筑物相邻的裸地容易被提取为建筑物变化的一部分,但SRCDNet可以有效地减少这些伪变化,如图7的第三行所示。
与BCDD数据集相比,CDD数据集具有更高的空间分辨率,因此包含了更多的细节变化,这些变化很难在4x双三次插值图像中重建;因此,与X1图像的实验相比,比较方法的准确度显著下降。虽然一些细节变化,如小巷和汽车,在比较方法的结果中很少见到,但SRCDNet是唯一能够检测到这些变化的方法,这进一步证明了SR模块在恢复空间和语义信息方面的有效性。除了提取更小的变化,SRCDNet在提取大面积变化,如土地变化和建筑物变化方面也表现出更好的性能。因此,定量和可视化的比较充分证明了SRCDNet在两个数据集的4x LR图像上的有效性。
\3) 在X8图像上的性能:X8实验比较了所有基线方法在8x LR图像上的性能,如表III所示。在BCDD数据集上,与X4实验相比,所有方法的准确度都进一步降低。FC-Siam-conc具有最高的准确度降低,其F1最低,为69.01%,其次是BiDateNet,其F1为70.01%。FC-EF的F1从76.69%降低到73.49%,它受分辨率差异的影响最小。FC-Siam-diff在基于U-Net的模型中获得了最高的F1准确度,为77.21%。STANet获得了77.31%的F1和69.05%的IoU。尽管分辨率差异很大,SRCDNet仍然优于所有的比较方法,获得了最高的F1为81.69%和IoU为69.05%。
从LR图像中恢复许多小物体是很困难的,因此,在CDD数据集上获得的准确度低于在BCDD数据集上获得的准确度。更具体地说,SRCDNet达到了最高的检测率,其F1为83.32%和IoU为71.40%,分别比X4实验中获得的结果低6.70%和10.46%。此外,BiDateNet的F1从86.28%降低到78.29%,而STANet的F1从86.49%降低到77.29%。由于三种FCN变体提取小变化的能力较差,在X8图像的实验中,这三种方法的准确度没有大幅降低。
X8图像的实验的可视化结果如图8所示。考虑到图8中第1-3行的BCDD数据集上的结果,可以看出,由于分辨率差异很大,很难基于双三次插值图像获得规则的建筑物边界。此外,还有很多漏报,即许多体积较小的房屋被漏掉。然而,SRCDNet可以更好地解决上述问题,生成更精确的变化结果。可以看出,尽管存在8x的分辨率差异,但由于有足够的先验知识,SR图像仍然可以很好地恢复建筑物的信息。
在CDD数据集上也发生了许多漏报,这与所有方法的低召回率相一致,如表I所示。这是因为通过双三次插值很难完全恢复初始HR图像中的信息,这些信息在8x下采样后被大大减少。因此,不仅小的变化,如小巷和汽车,而且一些建筑物变化也被漏掉或不完全检测出来。值得注意的是,与双三次插值图像相比,SRCDNet输出的SR图像更好地从8x LR图像中恢复了信息,这对后续的CD有很大的帮助,导致更完整和准确的变化结果。
C. 在Google数据集上的真实图像实验
在前两节中,我们在两个模拟数据集BCDD和CDD上进行了充分的消融研究和比较实验,验证了SRCDNet在解决CD中分辨率差异问题方面的有效性。接下来,我们将在Google数据集上进行比较实验,进一步测试模型在真实图像上的效果。此外,为了探索大数据集的应用潜力,我们还通过采用在BCDD和CDD上预训练的模型来应用于Google数据集,进行了迁移学习实验。
性能分析:所有的基线方法首先在Google数据集上从头开始训练,其中SRCDNet仍然取得了最好的准确度,其F1为77.13%,IoU为62.77%,表明该模型在具有4倍分辨率差异的真实图像上也有很好的效果。STANet和BiDateNet分别获得了75.27%和74.79%的F1,明显优于其他三种基于U-Net的模型,反映了注意力机制模型的增益效果。
图9展示了不同大小的建筑物的CD结果。可以看到,基于U-Net的模型的结果中存在许多伪变化,这可以归因于一些包括道路在内的不透水表面的变化很容易被误分类为建筑物。由于具有更好的判别能力,STANet和SRCDNet可以获得更准确的结果。此外,与双三次插值恢复的图像相比,SRCDNet恢复的图像可以更好地恢复建筑物的轮廓,从而进一步保证了建筑物CD的准确性。迁移学习分析:近年来,基于高分辨率遥感图像的CDD被提出用于测试CD算法,许多先进的算法在这些数据集上取得了良好的结果。然而,由于不同数据之间的域转移,一个在一个数据集上训练的模型有时很难直接应用于真实图像。目前,解决这个问题的主流方法之一是迁移学习。因此,这部分也设计了迁移学习实验,旨在探索将大数据集应用于真实图像的潜力。每个基线方法都会通过加载在BCDD和CDD上训练得到的最佳模型作为起点,在重建的具有4x分辨率差异的Google数据集上进行微调。
根据表IV,与从头开始训练相比,每个基线方法的准确度都通过微调得到了提高。对于FC-EF,FC-Siam-diff和FC-Siam-conc,BCDD上的预训练模型比CDD上的预训练模型具有稍好的增益效果。可能的原因在于,BCDD和Google数据集都关注建筑物变化,并且具有相似的高层特征,因此为上述结构相对简单的模型提供了更直接的增强。而对于BiDateNet,STANet和SRCDNet,情况则相反。这可能是由于CDD的数量更大,可以提供更多有利于这些复杂模型中注意力机制模块训练的多样化特征。总之,迁移学习实验表明,大数据集上的预训练模型可以改善真实图像上的CD结果。此外,与其他基线方法相比,BCDD和CDD上的预训练模型对SRCDNet具有最大的增益效果,其F1分别提高了2.49%和3.07%。
VI. 讨论
在本节中,我们对SRCDNet进行了进一步的实验和讨论:首先,使用不同的下采样策略得到的LR图像作为模型的输入,来测试模型对不同输入图像的鲁棒性;然后,设置比较实验来检验损失函数的敏感性。
A. 不同下采样策略的比较
如前所述,在比较实验中,BCDD和CDD中的第二阶段图像被双三次插值下采样,以获得模拟的LR图像。然而,在实际中,可用的图像可能更复杂。因此,为了验证模型对不同输入的鲁棒性,采用了不同的下采样策略,包括最近邻和双线性,来获得BCDD的两组更多的X4和X8图像进行比较。
表V中的结果显示,使用不同的下采样策略得到的准确度差异不显著,这表明SRCDNet对不同的输入具有良好的鲁棒性。对于X4图像的实验,“双三次”输入获得了最高的准确度,而对于X8图像的实验,“双线性”输入表现最好。“最近邻”输入在X4和X8图像的实验中都获得了最低的准确度。原因可能是最近邻下采样得到的LR图像包含更多的噪声,如图10所示。此外,SRCDNet可以为所有三种不同的输入生成具有良好视觉效果的恢复图像,这进一步验证了模型的良好鲁棒性。
B. 损失函数的敏感性实验
在训练SRCDNet的过程中,损失函数中的一个值2在平衡生成器优化的CD结果的收益方面起着至关重要的作用。因此,我们在BCDD上进行了敏感性实验,通过设置一组以0.25 x 10为步长的数字来探索损失函数的敏感性。结果如表VI所示。
BCDD数据集上的结果表明,不同的r值对变化结果有很大的影响,换句话说,损失函数对r值是敏感的。更具体地说,当r从0.25 x 10-3增加到1 x 10-3时,CD结果的准确度逐渐增加,而当r=1 × 10-3时,获得了最佳的准确度。当r>1 × 10-3时,准确度开始波动。基于上述结果,建议在应用时选择一个接近1 × 10-3的r值。
VII. 结论
我们提出了一个端到端的SRCDNet,用于具有不同分辨率的双时相图像。为了克服双时相图像之间的分辨率差异,我们采用了一个由生成器和判别器组成的SRM,用于将低分辨率图像恢复到高分辨率图像的大小,这在从低分辨率图像生成逼真的超分辨率图像方面已被证明是有效的。一个连体特征提取器从两个输入图像中提取多尺度特征:一个超分辨率图像和一个与不同时间戳对应的高分辨率图像,然后在这些特征上应用一个SAM,以捕获更多有用的通道和空间信息。SRCDNet采用深度度量学习来学习最终的变化图。消融实验验证了SRM和SAM在SRCDNet中的有效性。然后在BCDD和CDD上进行了比较实验,其中SRCDNet不仅在相同分辨率的图像上获得了最好的结果,而且在4倍和8倍不同分辨率的图像上也优于其他比较方法,这充分证明了SRCDNet在多分辨率CD方面具有一般性和实用性的能力。在具有4倍分辨率差异的Google数据集上进行的真实图像实验进一步验证了SRCDNet在真实图像上的有效性。在未来,我们寻求探索其他不同分辨率CD的方法,并促进深度学习在CD应用中的发展。










