
论文03:MF-SRCDNet
MF-SRCDNet:多传感器高分辨率遥感图像的多特征融合超分辨率建筑物变化检测框架
摘要
建筑变化检测对于评估土地利用、土地覆盖变化和可持续发展至关重要。然而,由于多传感器分辨率不匹配以及高分辨率图像特征的复杂性,传统的建筑物变化检测方法在准确性和适用性方面存在问题。在本研究中,我们提出了一种基于深度学习的多特征融合超分辨率建筑变化检测框架(MF-SRCDNet),包括超分辨率(SR)、多特征融合和变化检测(CD)模块。SR模块引入Res-UNet网络来生成具有丰富语义信息的统一SR图像。为了提高MF SRCDNet在复杂建筑检测中的性能,设计了一种有效的直角边缘视觉特征,并将其与具有改进特征提取器的CD模块融合。与不同的模块相比,所提出的方法在三个数据集中分别获得了0.881、0.857和0.964的最高FI值。结果还表明,在不同的双时间图像分辨率尺度差异实验中,鲁棒性得到了提高。本研究提出的方法可以应用于各种复杂场景,构建具有较强模型泛化能力的CD任务。
- 建筑变化检测的作用,或者本文的应用意义
- 传统方法存在准确性和适用性存在的问题以及原因是什么
- 本论文是怎么解决这个问题的。提出了MF-SRCDNet。
- MF-SRCDNet是基于什么的
- 网络结构包含了哪几部分
- SR模块的形式,引入Res-UNet原因
- 设计特色的直接边缘特征提高了性能
- CD网络的结构
- 说明本论文呢网络模型和方法的有效性和鲁棒性以及复杂场景的适用性。
1.简介
建筑物是人类活动的重要场所。在全球城市化日益加剧的背景下,对建筑物新建、拆除、改建和扩建的变化进行动态监测,对自然资源管理、城市可持续发展、灾害应急管理、,以及生态环境保护(Zhu et al.2022)。变化检测(CD)方法可以识别同一地理区域内不同阶段的遥感图像(RSIs)之间的差异(Singh,1989)。近年来,遥感技术迅速发展,世界各国都发射了高分辨率光学卫星,如QuickBird、Worldview-3和SuperView-1。高空间分辨率遥感图像RSI提供了更丰富的建筑轮廓和改进的纹理细节,并逐渐成为检测精细建筑变化的主要数据源。
- 建筑变化检测的意义
- 变化检测的作用
- 时代发展带来的遥感图像的变化
RSI构建CD的传统方法通常根据分析单元分为两类:基于像素的方法和面向对象的CD方法。然而基于像素的CD方法无法处理图像元素变化较大、经历大量”椒盐卷饼噪声“的场景。面向对象的CD方法的准确性严重受分割结果的影响,并且由于其分类器结构较浅,其深度特征提取受到限制(Wang et al.,2021)。深度学习(DL)近年来,可以从原始数据中自动提取复杂、层次和非线性语义特征的方法已被广泛用于高分辨率RSI特征智能CD(Shafique et al.,2022)。然而,大多数传统的DL策略使用后分类比较或直接分类方法。以前的CD结果的最终精度很容易受到分类图的影响,导致误差的积累(Ding et al.,2021)。后者可能导致图像中存在严重的“同义词谱”问题,无法有效区分变化特征信息。因此,可以同时输入和处理双时态图像的Siamese神经网络已逐渐成为CD的主流网络框架(Shi et al.,2021)。特别是,Chen和Shi(2020)通过将金字塔时空注意力机制引入Siamese神经网络,生成了更具鉴别力的时间和位置变化特征。使用两个公共数据集获得的结果具有较高的准确性。
- 传统遥感图像的CD分类
- 基于像素的遥感图像的传统CD存问题
- 基于面向对象的遥感图像的CD存在问题
- 深度学习可以应用于高分辨率RSI的CD
- 大多数DL使用的方法
- 后分类方法中的问题
- 直接分类方法中的问题
- Siamese神经网络成为主流CD网络原因
- Siamese神经网络如何更进一步提高了准确性。
然而,在现实世界的场景中,由于同源HR传感器观测的困难(例如,云和雾等恶劣天气条件)、成本、重访期和观测范围的限制,大多数双时间RSI在HR图像区域中只有低分辨率(LR)图像可用(Gong et al.,2016),而现有的CD方法可以很容易地应用于上述场景。为了解决双时间图像中的空间分辨率失配问题,先前的研究已经使用下采样或插值来统一HR和LR图像的分辨率。然而CD精度最终受到这两种方法的影响,因为前者导致了没有原始精确空间信息的下采样HR图片,而后者无法轻易恢复LR图像的附加语义信息(Wang et al.,2022a)。DL超分辨率(SR)重建方法以其强大的图像语义信息恢复能力克服了不同传感器固有分辨率的限制。这为多传感器HR图像的CD提供了巨大的可能性。刘等人(2021)结合SR生成对抗性网络(SRGAN)设计了一种基于SR的CD网络,并为模拟的双时间分辨率差图像获得了更好的构建CD结果。然而,在上述双时间HR图像的CD研究中,没有考虑真正的传感器和分辨率差异情况。同时,目前使用的大多数SR图像生成器仅使用残差网络,这可能会显著增加训练时间,并且不能完全保留用于重建的空间和局部细节信息。
- 为什么同源HR传感器中大多数双时间的遥感HR图像区域中只有低分辨率图像可用。
- 先前的研究方法是怎么解决分辨率不一一样的问题
- 下采样方法和插值方法都存在的问题
- 深度学习的的超分辨率重建方法具有哪些特点,为HR图像CD提供了可能性
- 刘等人(2021)结合了SRGAN的CD网络,获得了良好的构建CD效果。
- 刘等人(2021)的网络没有考虑传感器和分辨率的问题
- 以及大多数SR网络仅使用残差网络导致的问题
此外,由于图像之间特征的类间相似性和类内可变性,HR图像的光谱分辨率的降低阻碍了对城镇和村庄中微小而复杂的个体结构的检测(孙和王,2018)。最新的DL方法只通过使用更深的卷积层或不同的注意力机制来获取原始图像的抽象特征,而不考虑提取更有效地描述详细信息的衍生特征,如建筑物边缘和位置。一些研究已经克服了上述问题,并通过在原始HR图像中包含附加视觉特征来提高建筑CD的准确性。例如,Huang等人(2020)通过将从多时相RSI中提取的平面和垂直特征与光谱特征相结合,应用变化幅度阈值来更准确地提取额外的建筑面积。同样,张等人(2021)在多源高分辨率RSI的光谱特征中添加了额外的纹理和形状特征,并将其与所提出的W-Net网络融合,以获得比单一光谱特征输入法更高的建筑CD精度。此外,由于HR图像包含丰富的空间细节信息,添加更多的特征组合并不一定会产生更好的结果(Wang et al.,2022b)。相反,不正确地应用特征可能会降低构建CD的准确性。因此,有必要设计既能减少数据冗余又能减少背景的视觉特征图像的白噪声,并突出建筑物中的变化。
- HR图像对复杂的个体结构检测的较差的原因
- 最新的深度学习方法是怎么提取原始图像的特征的,忽略了衍生特征。
- 一些论文重视衍生信息。黄和张
- 盲目增加衍生特征检测存在问题,以及原因
- 需要精心设计衍生特征的检测
总之,在本文中,我们提出了一种基于DL的多特征融合SR变化检测框架(MF-SRCDNet),用于检测来自多个传感器的高分辨率RSI的建筑变化信息。所提出的MF-SRCDNet主要包括SR重建网络、多特征融合和CD网络三个模块,以解决双时图像分辨率不一致和图像特征提取困难的问题。本研究的主要贡献如下。
(1) 我们为多传感器HR图像的CD任务提供了一种新的SR网络。它生成的SR图像不仅与初始HR图像的分辨率相匹配,还保留了更多的空间细节,并学习了类似的传感器特征,如视角和照明,从而有效地减少了伪变化问题,提高了数据的可用性。
(2) 我们设计了一种直角边缘视觉特征,称为哈里斯线性线段检测(LSD)。提取的特征减少了传统特征中存在的数据冗余和背景白噪声问题,并显著增强了建筑物变化区域的位置和边缘信息。
(3) 我们将融合的多个特征与改进的特征提取器的双分支CD模块连接。这解决了现有CD策略中复杂场景的错误累积大和特征提取不足的问题。
(4) 我们介绍了一种新的具有挑战性的多传感器HR图像数据集(WXCD数据集),专门用于构建CD任务。所提出的MF-SRCDNet在三个CD数据集上进行了测试和评估,定性和定量结果都显示出优异的性能。它可以嵌入到其他基线网络中,以管理构建CD的不同复杂现实情况。
- 本论文的提出的网络基于什么解决什么问题
- MF-SRCDNet包含的模块
- 解决什么问题
- 本文贡献
- SR网络的作用功能,效果。
- 本文设计的衍生特征作用功能,效果
- 本文的CD模块的特点,解决了错误积累和特征提取不足的问题
- 介绍了多传感器的HR图像数据集(WXCD)数据集,它可以嵌入到其他的网络中。
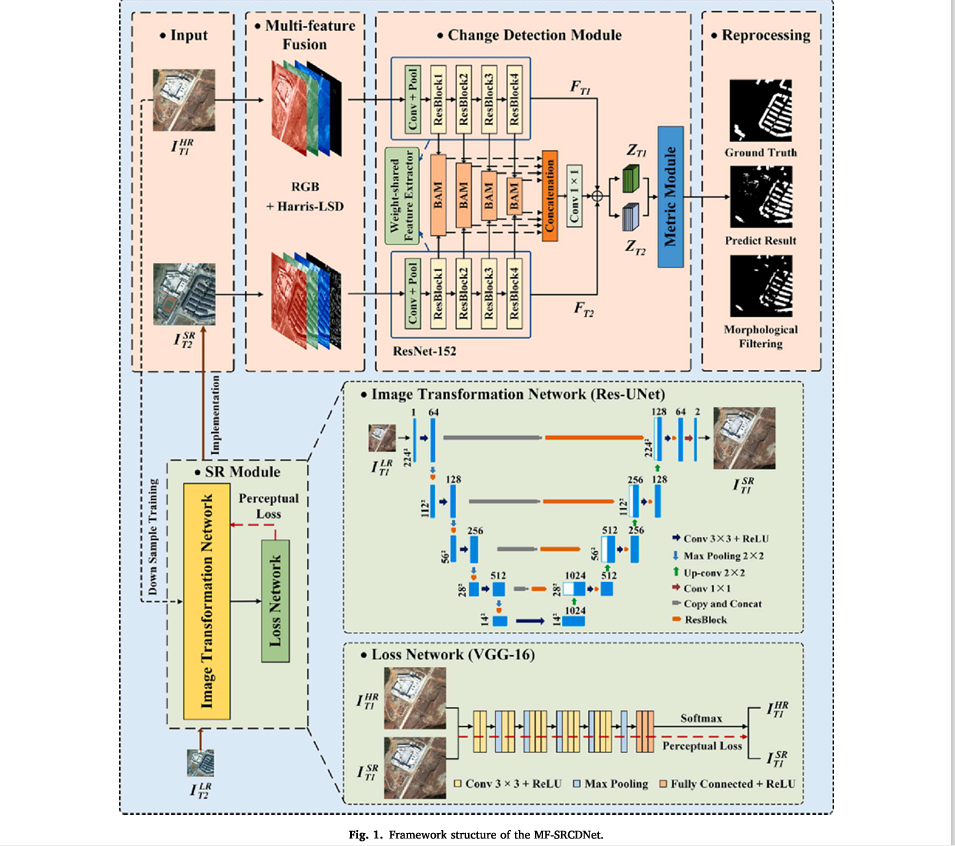
2.方法
2.1.MF-SRCDNet框架结构
所提出的MF-SRCDNet框架的三个主要组成部分如图所示。1。第一个组件是DL SR模块,用于将LR图像从多传感器双时间图像重建为SR图像。SR模块主要包括图像变换和损失网络。第二部分是多特征融合策略,用于进一步挖掘空间分辨率匹配后的双时间图像的纹理、形状和几何等多特征信息。第三部分是用于获取建筑变化结果的深度学习CD模块,主要包括特征提取器、金字塔时空注意力模块和度量模块。
- MF-SRCDNet网路的构成
- SR模块的构成和SR模块的作用
- 多特征融合策略模块的构成以及作用
- CD模块的构成和作用
提出的MF-SRCDNet框架流程如下:
(1) 构建CD所需的多传感器双时间T1 HR图像和T2 LR图像表示为$$I_{T1}^{HR}$$和$$I_{T2}^{LR}$$。首先,使用双三次插值算法将$$I_{T1}^{HR}$$下采样到与$$I_{T2}^{LR}$$相同的分辨率,并将生成的$$I_{T1}^{LR}$$和初始$$I_{T1}^{HR}$$作为样本训练集输入SR模块的图像变换网络。
(2) SR模块分为培训和执行阶段。在训练阶段,图像转换网络通过学习LR和HR图像之间的映射关系,将$$I_{T1}^{LR}$$转换为具有与$$I_{T1}^{HR}$$相同分辨率的$$I_{T1}^{SR}$$图像。然后,损失网络分别提取$$I_{T1}^{SR}$$和初始$$I_{T1}^{HR}$$的特征图。并引入感知损失函数来减少特征图之间的视差。图像转换网络随后根据损失值调整其权重因子,以生成与初始$$I_{T1}^{HR}$$相似的最终$$I_{T1}^{SR}$$。在执行阶段,T2阶段的LR图像$$I_{T2}^{LR}$$被输入到经过训练的SR模块,以生成具有丰富语义信息的$$I_{T2}^{SR}$$。
(3) 随后,计算空间分辨率匹配的双时间图像$$I_{T1}^{HR}$$和$$I_{T2}^{SR}$$的Harris LSD直角边缘视觉特征,并将其与图像的红-绿-蓝(RGB)光谱特征融合,作为深度学习CD模块的输入数据集。
(4) 最后,将CD模块应用于训练不同的特征组合数据集。使用在特征提取器中具有共享权重的改进的ResNet152网络来提取数据集的分层特征。然后在金字塔时空注意力模块中获得增强的多尺度时空关系特征。初始CD预测结果由度量模块生成,然后在使用形态学滤波算法对结果进行去噪后获得最终的构建CD图。
值得注意的是,我们提出的框架可以应用于具有不同周期和分辨率的各种CD任务:例如,与上述示例相比,我们的框架也可以应用于T1 LR图像和T2 HR图像的情况。
- 整个网络的运行流程
- 获得训练SR模块的低分辨率图片和高分辨率图片
- 在SR模块训练模式下判别生成SR图像和HR图像的loss
- 在SR模块正常下生成T2的SR图片
- 将T2的SR图片和T1HR图片进行LSD特征提取和RGB光谱特征融合。
- 融合的内容输入到CD中
- 经过改进的ResNet152和金字塔的时空注意模块获得多尺度的时空关系,由度量模块获得初始结果,滤波得到最终结构。
2.2.超分辨率(SR)模块
图像转换网络。我们使用Res-UNet(Cao和Zhang,2020)结合残差网络和U-Net的优势,用残差单元取代U-Net的普通卷积单元,以加速网络训练,方便信息传播,并提高网络在分辨率恢复过程中提取和保留空间细节信息的能力。Res-UNet网络的结构如图1所示。1,它包括三个组件:编码器、解码器和桥接器。编码器最初使用3 x 3卷积和整流线性单元(ReLU)来提取LR样本图像的浅层特征,然后通过2×2最大池化操作和残差联单元对LR图像进行下采样和提取深度特征。残差单元基于ResNet50(Lei和Shi,2021),它包含三个卷积层、ReLU层和批量归一化(BN)层,shortcut用于将输入图像X调整为不同的大小(如图2所示)。桥接器进行复制和残差连接操作,以将编码器的特征映射与解码器相结合。随后,解码器使用2×2上采样卷积来恢复特征图分辨率,以确保与HR图像的一致性。最后,通过1×1卷积层获得SR图像。
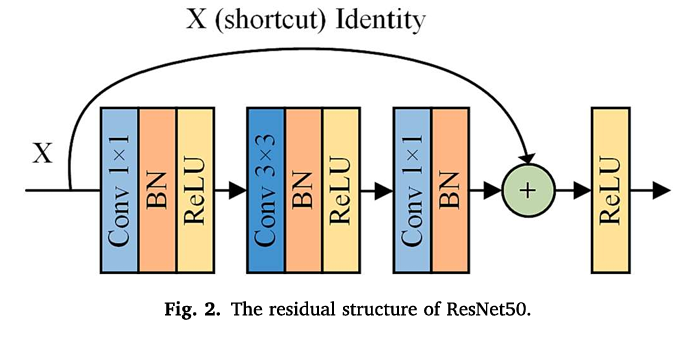
- SR模块的使用的工具,以及提供的效果
- SR模块的构成
- 解码器的构成,作用
- 残差单元的构成
- 桥接器和解码器的作用
损失网络。在接收到Res-UNet输出的SR图像后,我们使用具有固定参数的预训练VGG-16(Ge et al.,2021)作为损失网络,将其与原始HR图像分离(如图1所示)。VGG-16具有五个卷积层、三个完全连接层和一个使用softmax函数的图像分布输出。使用最大池操作将这些层彼此隔离。此外,它包括一系列感知损失函数(Johnson等人,2016),用于减少SR图像和原始HR图像之间的特征图差异,从而提高计算效率。最终结果表示SR图像和原始HR图像之间的连续接近度。感知损失计算如下:
$$
Loss_{per} = \frac{1}{C * H * W}||N(I_{T1}^{SR})-N(I_{T1}^{HR})||^2
$$
其中,C、H和W分别表示特征图的通道数量、长度和宽度,N表示损失网络。
- 损失网络的构成
- VGG-16网络构成
- 最大池化层的作用
- VGG-16的损失函数的作用
- 损失计算方法
2.3.多特征融合策略
为了帮助CD模块识别建筑物的变化和不变区域,我们在基于图像边缘、形状和几何信息的空间分辨率匹配后,提取了双时间图像的Harris-LSD右边缘视觉特征。为了进行充分的比较,我们还提取了形态构建指数(MBI)特征和非最大抑制索贝尔(NMS-Sobel)特征。然后,我们将这些特征中的每一个与图像光谱特征融合,作为CD模块的输入数据集。
- 为了帮助CD模块识别建筑的变化和不变化的区域,设计那些特征以及特征提取。
Harris角点检测器和线段检测器结合了直角边缘特征。建筑物通常以大量的哈里斯角点和直线段为特征。然而,单次使用角点特征往往会导致信息丢失,而单次使用线段特征会导致大量重复的无意义线段(Hao et al.,2021)。因此,我们使用Harris角点检测器和LSD算法的组合来提取建筑区域的直角边缘特征。Harris LSD直角边的定义如下。在距离提取的Harris角点一定的欧几里得距离内,存在两个彼此近似垂直的直线段,并且在长度上满足一定的要求。Harris LSD直角边被定义为满足上述要求的两个直线段。该计算公式如下:
$$
|\lambda_{i} - 90^{\circ}| < \varphi _ {1}
$$
$$
\begin{cases}
D_{1} < \varphi_{2}
\
D_{2} < \varphi_{2}
\end{cases}
$$
$$
\begin{cases}
\varphi_{3}<l_{1}<\varphi_{4}
\
\varphi_{3}<l_{2}<\varphi_{4}
\end{cases}
$$
其中:$$\lambda_i$$表示两条直线段之间的角度;$$D_1$$和$$D_2$$表示从提取的Harris角点的最近端点起的两个直线段的欧几里得距离;并且l1和l2表示两个直线段的长度;$$\varphi_{1}$$、$$\varphi_{2}$$、$$\varphi_{3}$$和$$\varphi_{4}$$分别表示已知角度阈值、距离阈值、最小长度阈值和最大长度阈值。在单独检测角点和线段后,我们保留任何被视为直角边的线段;否则,线段将被删除。Harris LSD特征用于消除特征冗余、背景白噪声和非建筑区域,提取的建筑直边更清晰、更精确。在该实验中,用于确定角点的阈值被设置为0.08,$$\varphi_{1}$$、$$\varphi_{2}$$、$$\varphi_{3}$$和$$\varphi_{4}$$分别被设置为0.5、50、10和150。计算出的Harris LSD特征如图3(b)所示。
- Harris LSD 直角起到了什么作用
- 怎么设计获得Harris LSD直角,如何计算的,以及其中的常量设置是什么。
形态构建指数特征。MBI使用一组形态学算子(如形状、方向、亮度和对比度)提取建筑结构特征(Huang和Zhang,2011)。其计算如下:
$$
MBI = \frac{\sum_{d,s}DMP_{WTH}(d,s)}{D \times S}
$$
其中d和s分别表示线性结构元件的方向和比例。DMPwth表示重建形态白顶帽(WTH)值之后的微分形态轮廓(DMP)。D和S分别表示可以确定建筑轮廓的方向和比例的数量;$$ S=((s_{max} - s_{min})/ \bigtriangleup s) + 1 $$ 。在本研究中,线性结构元素smin的标度设置为3,smax设置为30,$$\bigtriangleup s$$设置为1。计算图像的MBI特征如图所示。第3(c)段。
- 形态构建指数特征MBI作用,计算公式,常量设置。
非最大抑制索贝尔特征。在检测过程中,原始的Sobel边缘检测算法可能导致大量杂乱和错误检测的边缘(例如,边缘位置附近的屋顶线)。因此,我们使用非极大值抑制算法消除了大多数非边缘点(Lei et al.,2022)。Sobel计算之后在(x,y)位置处的梯度图像M(x,y)的非最大抑制计算如下:
$$
G(x,y) = \begin{cases}
M(x,y),M(x,y) >=M(x-1,y) & M(x,y) >= M(x+1,y)&\theta(x,y)=0
\
M(x,y),M(x,y) >=M(x-1,y-1) & M(x,y) >= M(x+1,y+1)&\theta(x,y)=1
\
M(x,y),M(x,y) >=M(x,y-1) & M(x,y) >= M(x+1,y+1)&\theta(x,y)=2
\
M(x,y),M(x,y) >=M(x-1,y+1) & M(x,y) >= M(x+1,y-1)&\theta(x,y)=3
\end{cases}
$$
其中,G(x,y)是非最大值抑制过程后的新梯度值,并完成计算以获得NMS-Sobel特征,如图所示。第3(d)段。

- 原始的Sobel算法存在的问题,以及本文做出的改进方法,以及计算方法。
2.4.变化检测模块
在获得具有匹配分辨率的多特征融合图像后,进行了构建CD任务。MF SRCDNet使用一个改进的STANet PAM模型来检测变化,该模型是一个具有Siamese结构的DL网络。
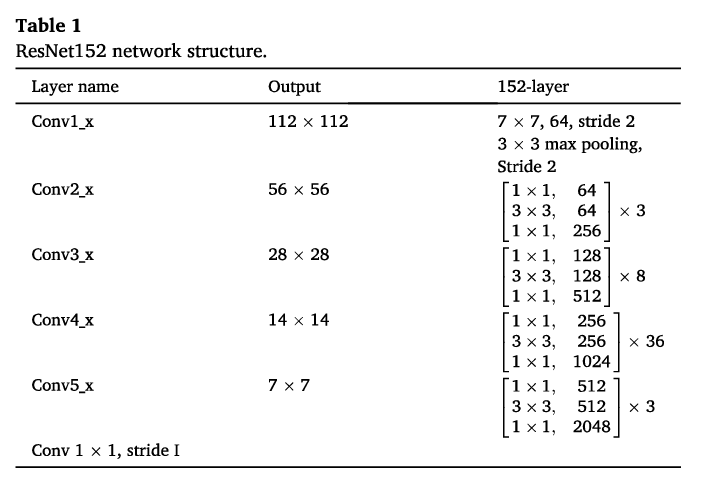
特征提取器。删除全局池化层和完全连接层后,我们使用ResNet152(赵等人,2022)作为特征提取器,这是一个比原始STANet的ResNet18层更深的网络,可以训练来提取更复杂的图像特征。表1列出了修改后的ResNet152网络结构。首先,使用7×7卷积核提取图像的浅层特征。然后使用步长为原始图像大小的2到一半的最大池化层来减少特征图。为了进一步提取比ResNet18的通道深度多1024和2048维的抽象图像特征,我们使用了四个深度残差块。
- 如何构建CD任务,MF-SRCDNet使用模型以及网络结构
- 特征提取器ResNet152使用的网络的网络结构,作用
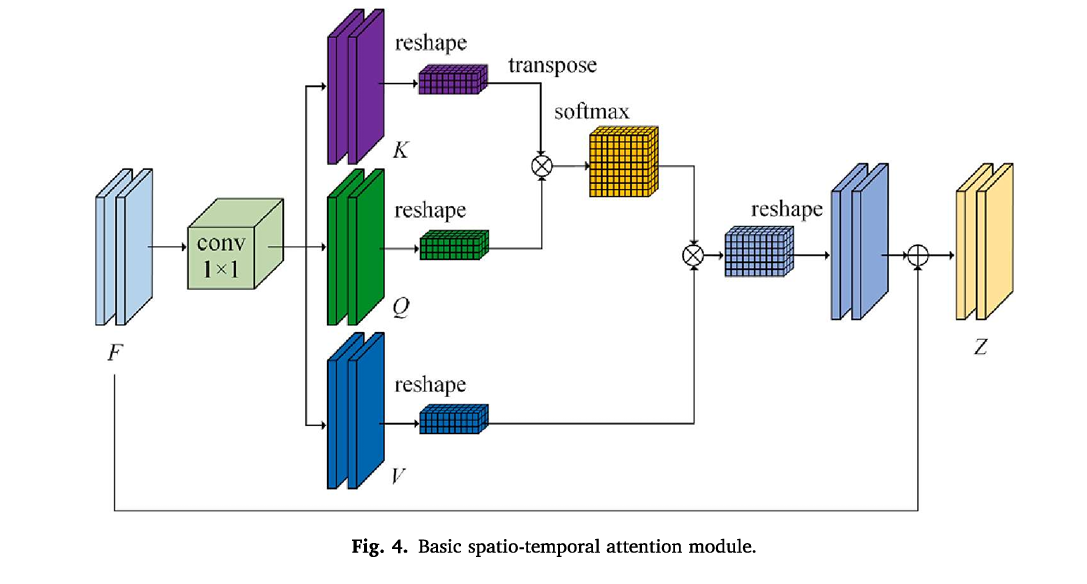
金字塔时空注意力模块(PAM)。如图1所示,PAM包含四个分支,每个分支将特征张量均匀地划分为与尺度相关的子区域。然后使用基础时空注意力模块(BAM)在每个分支中更新子区域像素的局部注意力特征。(程等,2021)。最后,使用1 x 1卷积运算来连接来自四个分支的更新特征,并将特征图放大到原始图像大小。此外,多尺度全局时空注意力特征$$Z_{T1}$$和$$Z_{T2}$$是通过将它们与原始残差特征张量$$F_{T1}$$和$$F_{T2}$$相加而形成的,从而增强了模型获取详细信息的检测能力。每个分支的BAM结构如图4所示。它结合了将ResNet152在双时间图像中提取的中间特征转换为特征图F,通过卷积运算将其转换为三个特征图K、Q和V,然后使用一系列变形和加权运算以获得局部注意力特征Z。
- PAM的组成作用,ZT1和ZT2是获得方法,详细的由F得到Z的过程。
度量模块。度量模块通过阐明特征之间的欧几里得距离来确定双时间特征之间的相似性,并使用批量平衡对比度损失(BCL)(Chen和Shi,2020)来优化距离图和地面实况之间的差距,从而生成受伪变化区域影响较小的距离图。最后,使用直接的阈值分割,从距离图中导出精确的CD图。
- 度量模块的作用,使用的损失函数,工作原理,最后如何得出精确的CD图。
3.实验结果及分析
3.1.数据集描述
(1) WXCD数据集。由于只有少数多源RSI数据集可用于CD任务,我们手工制作了一个数据集,专门用于构建具有多个传感器的高分辨率RSI的CD。表2中列出了所使用的具体参数。选择无人机(UAV)和SuperView-1(SV-1)图像作为RGB波段的原始图像,并使用ArcGIS软件手动对两幅时间图像之间有显著变化的建筑区域进行矢量注释,并将其转换为Tiff格式。场地独特的自然和人文环境、复杂多样的建筑形式和场景,以及不同拍摄角度和光线变化的双时间图像的传感器特性,对建筑CD任务的挑战比其他公开可用的数据集更大(如图所示)。第5(1)段。该数据集可在https://doi.org/10.6084/m9.migshare.22231501.v1上找到。
- WXCD数据集是什么数据集,为什么自己做数据集,以及做的方法流程。怎么获得
(2) GZCD数据集(Peng et al.,2020)。该数据集位于中国广州郊区,在收集期间,广州经历了快速的城市化,并包含了建筑形状和大小的许多变化。它有复杂多样的建筑类型,从大型工厂到小型移动房屋(如图所示)。第5(2)段。由于该数据集的双时间图像具有相同的分辨率,因此它们仅用于所提出方法的无分辨率差异实验,以测试模型的泛化能力。表2中列出了本研究中使用的参数。数据集来源于https:/github.com/daifeng2016/Change-DetectionDataset-for High Resolution Satellite Imagery。
- GZCD数据集包含的内容,在本实验中的作用。
(3) BCDD数据集(Ji et al.,2018)。该数据集的双时间图像具有不同的空间分辨率,为多源HR图像构建CD实验提供了数据支持。我们在数据集中选择了一个形状和类型各异的建筑密集区域作为实验区域(如图5(3)所示),具体参数如表2所示。数据集来源于http://gpcv.whu.edu.cn/data/building_dataset.html。
- BCDD数据集的内容,以及在在本论文中作用。
3.2模型实施细节
软件和硬件环境配置。这项研究中使用的计算机配备了一块11GB的NVIDIA GeForce GTX 2080超级显卡和一块32G的内存条。所提出的方法是使用PyTorch框架实现的。
超分辨率重建。我们使用三种SR方法,双三次插值(bicubic)、CycleGAN和MF-SRCDNet,来重建多传感器HR图像。我们将WXCD数据集的SV-1时间图像0.5米的空间分辨率重新配置为0.2米,以匹配无人机时间图像的空间分辨率。随后,我们将BCDD数据集的时间图像0.2 m的空间分辨率重新配置为0.075 m,以确保与后时间图像的空间分辨率一致。此外,考虑到GZCD数据集不存在真正的分辨率差异,我们只对其进行了特征融合和CD方法的比较实验。
- 我们采用了什么方法构建超分辨率重建
- 对数据集进行了什么处理
特色组合训练模式。我们将融合的多特征图像分为四种不同的组合模式:RGB、RGB+MBI(RGBM)、RGB+NMS-Sobel(RGBN)和RGB+Harris LSD(RGBH)。
样本分配。我们根据一般的深度学习样本比例,将数据集测试区域随机划分为训练、验证和测试区域,其中训练、验证、测试样本集的比例为6:1:3。
模型训练参数设置。该方法的训练参数为:训练轮20个epochs;学习率为0.001;激活函数为ReLU函数,batch设置为4个,优化算法采用sto-custic梯度下降法;损失函数使用批量平衡对比度损失来减少正负变化样本的不平衡效应。
预处理方法。我们使用形态学滤波算法对所有CD结果进行去噪。形态学滤波通过扩张、侵蚀和打开或关闭操作改进获得的图像质量。在本研究中,Erode运算主要使用ENVI 5.3软件进行,我们将卷积核设置为5×5,循环设置为1。
3.3.比较方法和评估指标
3.3.1.比较方法
为了验证MF-SRCDNet的有效性,我们将其与其他SR方法以及深度学习CD方法进行了比较和分析。SR方法包括Bicubic(Tu et al.,2017)和CycleGAN(Li et al.,2021)。CD方法包括U-Net(Song et al.,2021)、PSPNet(Shen et al.,2022)、Faster R-CNN(Bai et al.,2020)、DeepLabV3+(Yao等人,2021)和Mask R-CNN(Han等人,2021年)。
值得注意的是,上述五种深度学习CD方法对双时间图像差异策略数据集进行了实验,结果表明,差异策略可以获得比融合策略更高的精度(Wang et al.,2018)。这是通过从前时间图像中提取后时间图像的逐像素子牵引来获得的,用于与所提出的框架的Siamese神经网络进行比较。
- 与不同的SR网络和CD方法进行了比较,验证MF-SRCDNet的有效性。
- 差异策略和融合策略的比较,以及为什么差异策略比融合策略更好的效果
3.3.2评估指标
结果可分为四种情况:真阳性(TP)、假阴性(FN)、假阳性(FP)和真阴性(TN),这取决于在变化和不变区域中对模型的检测。TP是被正确检测为变化区域的像素的数量;TN是被正确检测为未改变区域的像素的数量;FP是将未改变区域错误地检测为改变区域的像素的数目;FN是将改变的区域错误地检测为未改变的区域的像素的数量。我们使用基于像素的混淆矩阵来计算这些值,并应用精度(Pre)、召回率(Rec)、F1分数(F1)、总体精度(OA)和kappa系数(KC)五个精度评估指标来检查每个模块算法在构建多源高分辨率RSI CD时的预测性能。每个精度评估指标的具体方程式如下:
$$
Pre = \frac{TP}{TP+FP}
$$
$$
Rec = \frac{TP}{TP+FN}
$$
$$
F1 = 2 \times \frac{Pre \times Rec}{Pre \times Rec}
$$
$$
OA = \frac{TP+FN}{TP+FN+FP+TN}
$$
$$
R = \frac{(TP+FN)(TP+FP)+(TN+FN)(TN+FP)}{(TP+TN+FP+FN)^2}
$$
$$
KC = \frac{OA-R}{1-R}
$$
3.4.实验结果的比较
3.4.1.定量比较
根据表3至表5,首先,MF SRCDNet重建的WXCD和BCDD数据集大多优于Bicubic和CycleGAN方法在构建每个特征组合的CD的精度方面,最高的F1值分别为0.881和0.964,最大值分别为0.092和0.044。此外,在所有三个数据集中,RGBM、RGBN和RGBH分别获得比RGB特征更高的F1、KC和OA。第三,考虑到多特征融合的CD精度,RGBH在不同数据集中的KC优于其他特征组合。GZCD数据集的最小改进为0.033,WXCD(MF-SRCDNet)数据集的最大改进为0.104。尽管RGBM和RGBN也具有高CD精度,但它们的结果不太稳定。
根据表6至表8,不同CD方法的MF-SRCDNet重建的WXCD和BCDD数据集的CD精度仍然大多超过Bicubic和CycleGAN方法,其中FI值的最小和最大改进分别为0.024和0.007,以及0.186和0.25。其次,U-Net、PSPNet、deep-LabV3+、Faster R-CNN和Mask R-CNN这五种深度学习CD方法在CD方面存在很大差异在三个数据集中,特别是在KC度量的tems中,与MF-SRCDNet相比的准确性。平均而言,在每个数据集中,MF SRCDNet比次高级算法的改进幅度为0.091。这可能与早期的图像处理策略有关,并且MF SRCDNet的暹罗结构在图像处理过程中产生的累积误差低于差分策略。
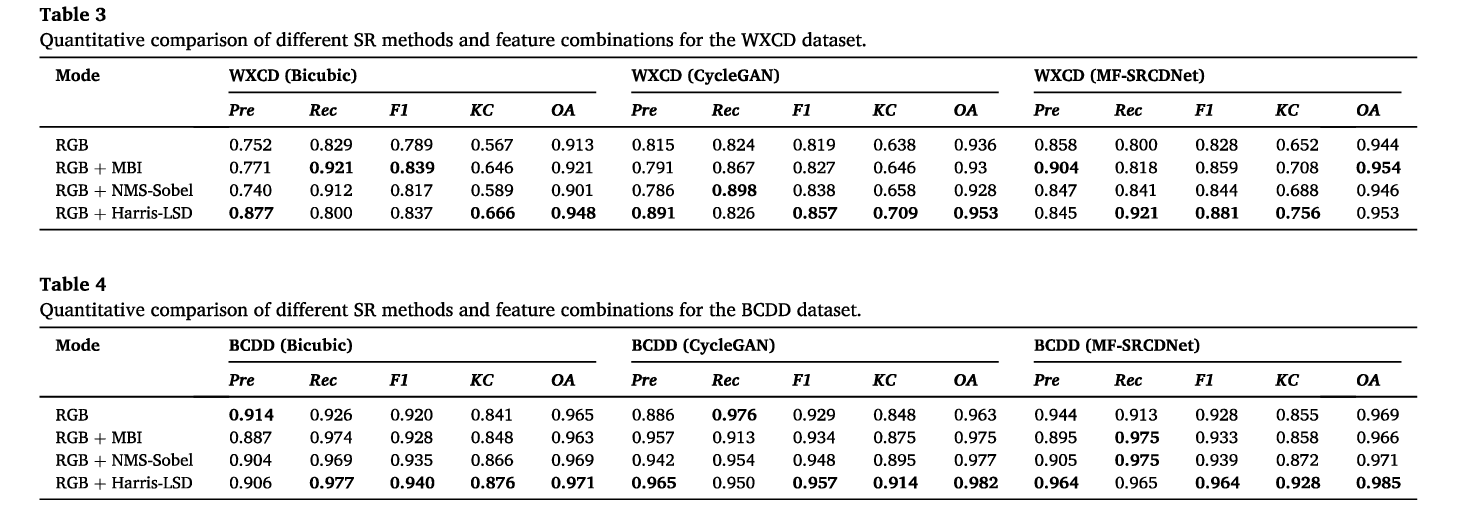
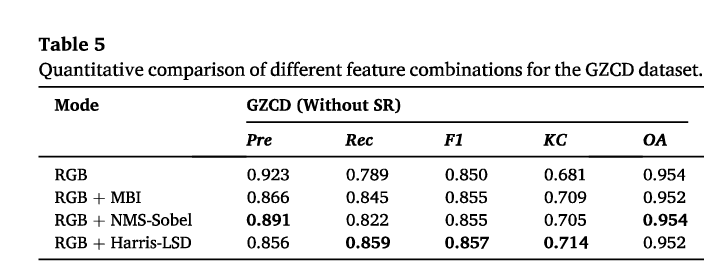
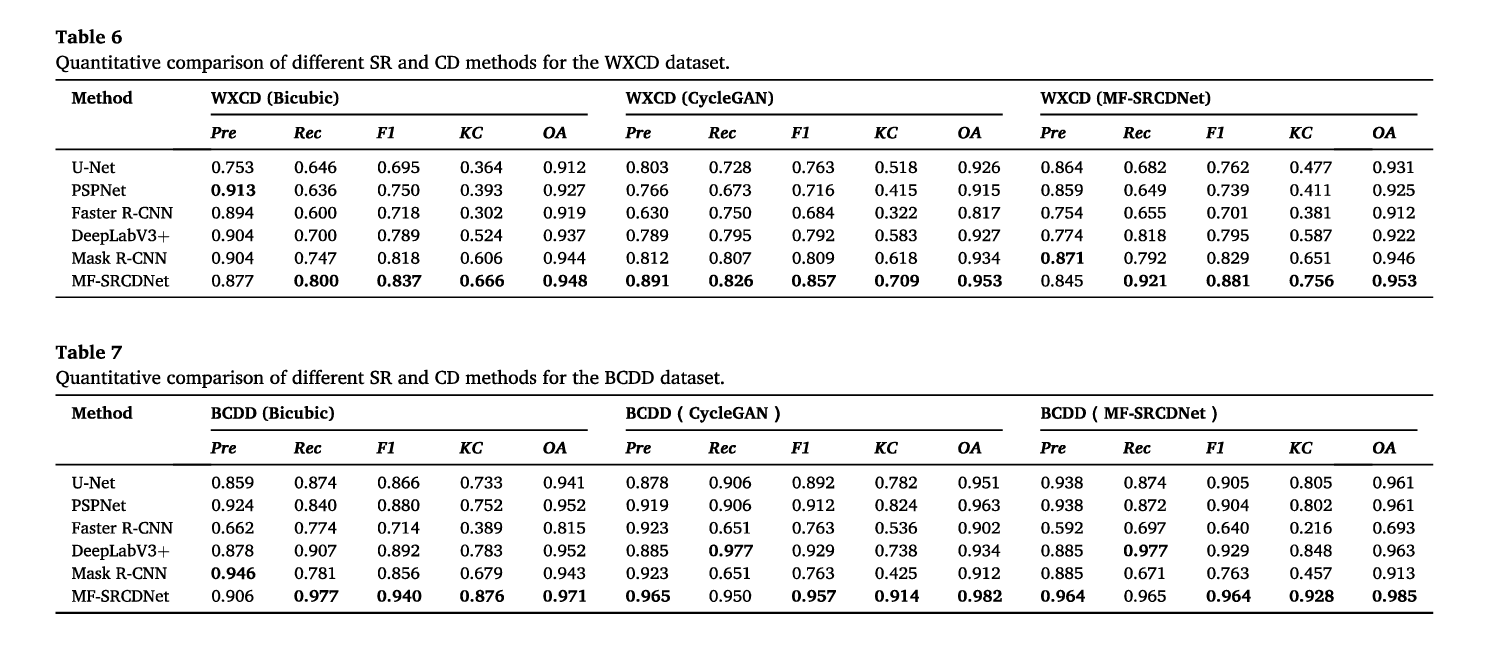
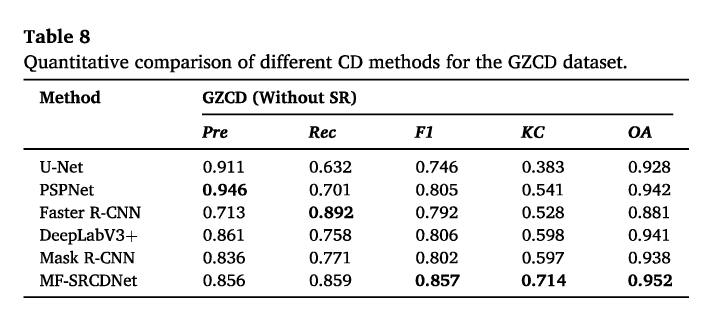
3.4.2.视觉对比
如图6和图7所示(TN、TP、FN和FP的解释见第3.3.2节),MF SRCDNet重建后的每个数据集的大多数对建筑物CD显示出最佳的视觉效果。特别是,对于WXCD数据集的每个特征组合,所提出的方法检测到的建筑物的FP比Bicubic和CycleGAN方法少得多,如图6所示。对于WXCD数据集,总体CD效果也优于其他两种SR方法,如图7所示。这对应于表3中较高的Pre和表6中较高的F1量化结果。对于BCDD数据集,所提出的方法检测到更完整的建筑物,这对应于表4和表7中较高的Rec。
对于不同的特征组合,在大多数数据集中,RGBH优于其他特征组合(图6)。特别是,其他特征组合经历了严重的建筑边界溢出,而RGBH可以更好地区分密集建筑区域中的变化区域,并保留更完整的间隔。就整体视觉效果而言,这些附加的特征组合仍然优于从RGB特征中获得的CD结果。
对于不同的CD方法,MF-SRCDNet在每个数据集的密集、连续的建筑集群、大型体育场和其他变化区域中检测到更准确、更完整的边缘信息,总体CD效果优于其他CD方法(图7)。U-Net和PSPNet检测到了极为破碎的建筑边缘,并包含大量的FN和FP。DeepLabV3+结果也错误地检测到了更多的像素,尽管FN减少了。更快的R-CNN对建筑位置变化有相对较好的识别能力;然而,由于它只能输出方形检测帧,结果无法准确描述建筑占地面积,从而产生许多溢出。Mask R-CNN非常重视建立变化边界;然而,结果也包含更多的遗漏检测。
- 从视觉上对比了不同的SR策略和不同的SR的CD策略的效果。


4.消融实验与讨论
4.1分辨率尺度差异的影响
为了进一步验证MF-SRCDNet的稳健性,我们根据密集建筑的后时间图像的分辨率尺度进行了两组比较实验:
(1)四倍空间
分辨率小尺度差异实验(X4);首先,我们使用双三次插值将WXCD和BCDD数据集的T2时间图像下采样到与T1时间HR图像分辨率相差四倍的图像。然后通过SR方法将这些模拟的LR图像重建为具有与Tl时间图像相同分辨率的SR图像;然后我们使用它们作为输入数据集进行后续处理。(2) 八倍空间分辨率大尺度差异实验(X8):该实验的图像操作与X4实验相似。
- 如何获得低分辨率的图片
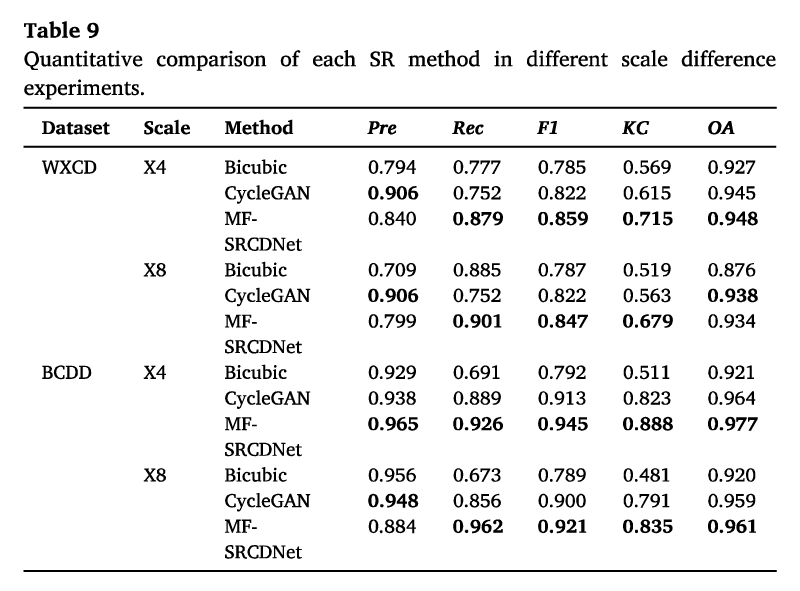
不同规模差异实验的表现。如表9所示,与之前直接基于SR图像实验的表3相比,在两个数据集的X4实验下,所有SR方法的CD精度都有所降低。在WXCD数据集中,Bicubic方法显示F1和KC值的下降幅度最大,分别为0.052和0.097;CycleGAN方法显示F1和KC值分别为0.035和0.094;MF SRCDNet在X4标度差处保持了最大CD精度,FI和KC值分别为0.859和0.715,分别仅下降了0.022和0.041。当标度差增加到X8时,所有方法都进一步降低了基于X4的CD精度。特别是,在WXCD数据集中,Bicubic、CycleGAN和MF-SRCDNet方法的KC值分别下降了0.05、0.052和0.036。在BCDD数据集中,上述方法的KC值分别降低了0.03、0.032和0.053。
图图8显示,在WXCD和BCDD数据集的X4实验中,双三次方法都有很大程度的漏检。这种情况在具有较大尺度差异的X8实验中更为严重,并且大型白色平台被错误地检测为建筑变化区域(图8,第三行Bicubic)。CycleGAN的CD可视化略好于Bicubic方法,但在X4实验中,它不能有效区分规则的建筑变化边界,并且观察到大量的溢出,在X8实验下,该方法遗漏了大量的建筑变化像素,尤其是对于大体积建筑(图8,第四行Cycle-GAN)。MF-SRCDNet的CD可视化结果较少受到分辨率下降尺度差异的影响,并且可以更清楚地检测每个数据集在不同尺度差异实验下建筑物足迹形成的变化。值得注意的是,与Bicubic和CycleGAN不同,MF-SRCDNet可以通过X8实验检测小建筑面积的变化信息(图8,第四行MF-SRCDN),而当两种SR方法都有大量遗漏检测时,MF-SRC DNet检测到更多的建筑变化区域。
- 在4X情况下和8X情况下分别比较了CD的效果
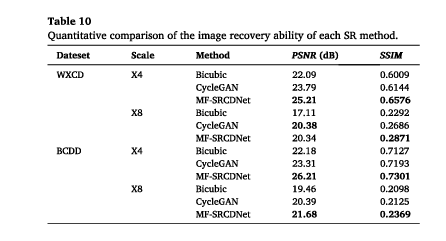
图像重建的质量。我们使用两个指标,峰值信噪比(PSNR)和结构相似性(SSIM),来定量比较重建图像的质量。从表10所示的总体来看,在每个数据集X4实验中,每个SR方法的图像质量都略高,但在所有X8实验中都观察到了显著的下降,特别是在SSIM中。对于特定的比较,Bicubic方法的PSNR和SSIM在两个数据集中都具有最低值。Cycle-GAN的恢复图像质量显示出一些改善,但这可能是由于其循环结构过于关注来自不同传感器的图像特征之间的转换,导致在HR图像中生成伴随着杂乱光谱色块的SR图像(图7,第二行T2 CycleGAN)。尽管MF-SRCDNet在所有数据集实验中都获得了更高的图像质量,这表明它保持恢复接近原始图像的能力比其他方法更强,但在X8实验中,它与参考图像的结构信息存在很大差距。
- 设计了两个指标比较了不同的SR策略下的图片效果

4.2.特征融合的影响
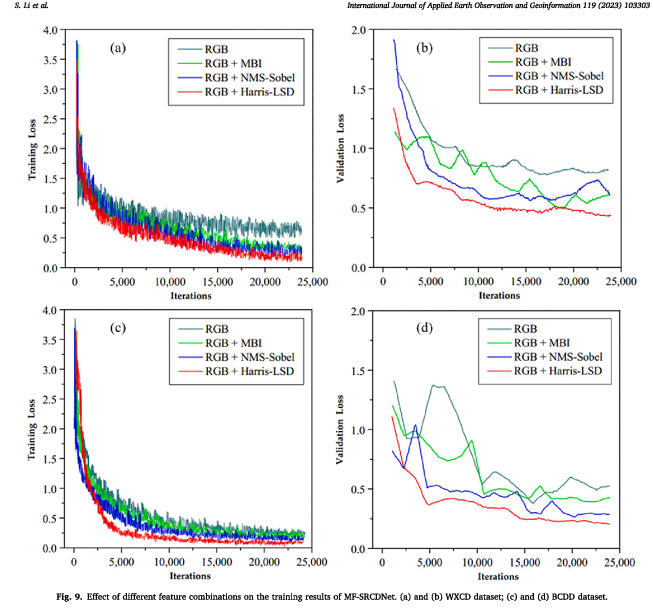
为了验证不同特征组合模式对所提出的MF-SRCDNet的影响,我们使用不同的特征融合策略在WXCD和BCDD(MF-SRCDN)数据集上训练模型,并获得训练和验证损失曲线。图9显示两个数据集的RGBH损失曲线都表现出更快的收敛速度,表明包含Harris LSD特征可以提高模型的训练效率;RGBH的损失曲线振荡较小,突出了其在训练和验证过程中的卓越稳定性;此外,在两次验证损失中,只有RGBH降至0.5和0.25以下,突显了其提高模型训练精度的能力。虽然RGBM和RGBN也表现出相对较强的训练效果,但它们在稳定性和准确性方面存在一些缺点。
- 研究不同的融合策略对训练效率,稳定性,精度的影响
4.3.ResNet层数的影响
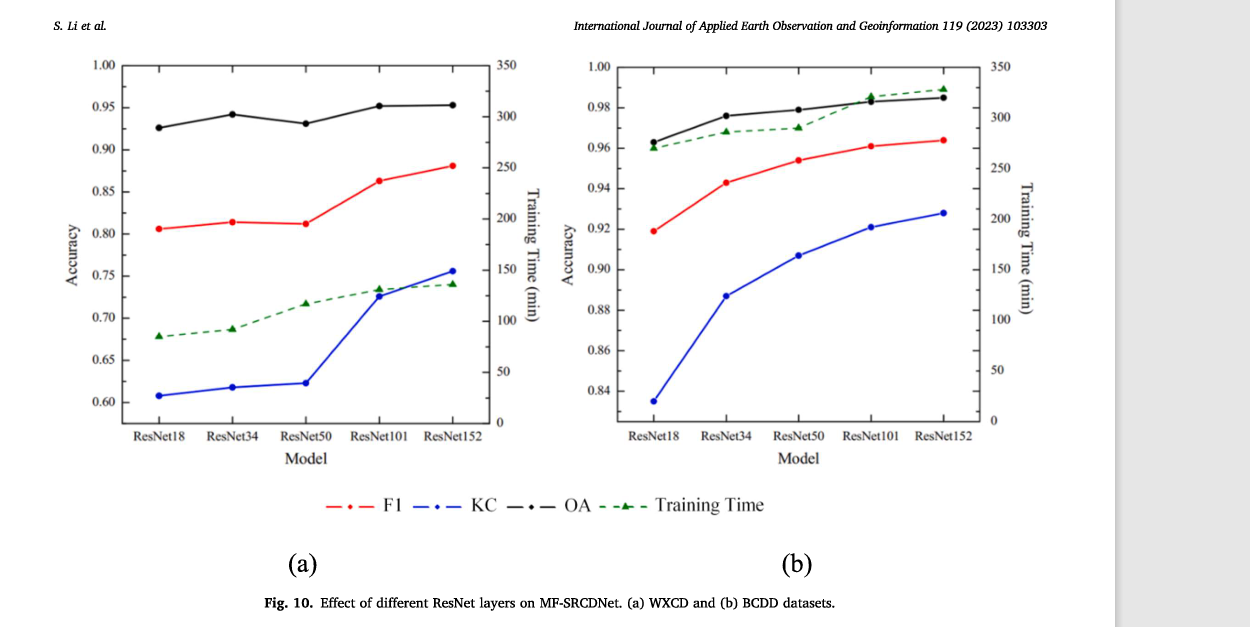
为了验证所提出方法提高ResNet层数的有效性,我们将预先训练的ResNet18、ResNet34、ResNet50、ResNet101和ResNet152迁移到STANet PAM模型的特征提取层,并在基于MF-SRCDNet的WXCD和BCDD数据集上获得了CD的准确性和效率。图10
表明ResNet的不同层对所提出方法的CD结果的影响是显著的,并且基于ResNet152的层可以获得比其他层更高的F1、KC和OA值,同时还保持尽可能低的训练经过时间。
- 探讨ResNet的层数对CD的影响
4.4.讨论
通过在多传感器高分辨率RSI中构建CD的对比实验,我们可以得出以下结果分析。
(1) 所设计的SR模块可以解决双时间图像中分辨率不匹配的问题,同时在更大程度上保留重建的高分辨率图像中的语义信息。与其他SR方法相比,我们的模块可以在不同分辨率尺度的差异实验中更稳定地检测建筑物的变化。然而,它在具有极其大规模差异的场景中有局限性,其中图像空间结构难以恢复(图8,第八行T2 MF-SRCDNet图像)。
- SR模块的有效性和不足
(2) 提取并融合的视觉特征Harris-LSD可以有效地辅助CD网络检测建筑物的角点位置和直角边缘信息,在各种复杂场景中表现出更好的适应性。然而,由于对圆形或拐角建筑物不敏感,该特征可能会出现漏检问题(图6,第一行MF-SRCDNet)。此外,它主要关注边缘信息,导致一些大型建筑的内部信息检测不完整(图8,第四行MR SRCDNet)。
- 提出的Harris-LSD等方法辅助CD网路检测的有效性和不足
(3) 改进的CD网络在所有三个具有挑战性的数据集中都实现了更好的变化检测准确性和可视化,具有更强的泛化能力。然而,由于不同传感器的限制,真实CD场景的可用样本通常是稀疏的,并且DL模型需要大量的训练样本,这可能导致模型训练不足。
- CD网络的有效性以及不足
此外,本研究侧重于建筑变化和非变化的二元变化检测,考虑较少捕捉更深层次的“从到”语义变化信息,例如从住宅建筑到商业建筑的变化。未来可以通过研究少量镜头学习方法和语义变化检测来改善这些情况。
- 本论文呢着重点和没考虑的问题
5.结论
在本研究中,我们提出了一种用于多传感器HR图像的多特征融合SR构建变化检测框架(MF-SRCDNet)。首先,我们设计了一个基于Res-UNet、VGG16和感知损失的新SR模块,将分辨率不匹配的双时间图像重建为SR图像,并有效地恢复图像的空间细节信息,从而提高多源RSI的数据可解码性。此外,我们提取了一个新的视觉特征Harris-LSD,并将其与图像光谱特征融合。这种融合的特征数据集增强了图像的建筑位置和边缘特征,减少了建筑CD任务中位置不准确和边缘不清晰的问题。最后,我们修改了ResNet152网络,并将其部署在CD模块的特征提取器中,以增强模型提取复杂场景特征的能力。我们在三个数据集中验证了MF-SRCDNet的稳健性和有效性。与其他SR方法、特征组合和CD方法相比,MF SRCDNet在不同分辨率差异的情况下实现了更好的CD性能,并检测到更全面的建筑物和更准确的边缘,尤其是在小型建筑物上。因此,它在检测建筑物的详细信息方面显示出综合优势
改变










